QWEN CHAT GITHUB HUGGING FACE MODELSCOPE DISCORD
Introduction
Last December, we launched QVQ-72B-Preview as an exploratory model, but it had many issues. Today, we are officially releasing the first version of QVQ-Max, our visual reasoning model. This model can not only “understand” the content in images and videos but also analyze and reason with this information to provide solutions. From math problems to everyday questions, from programming code to artistic creation, QVQ-Max has demonstrated impressive capabilities. Though this is just our first version, its potential is already eye-catching.
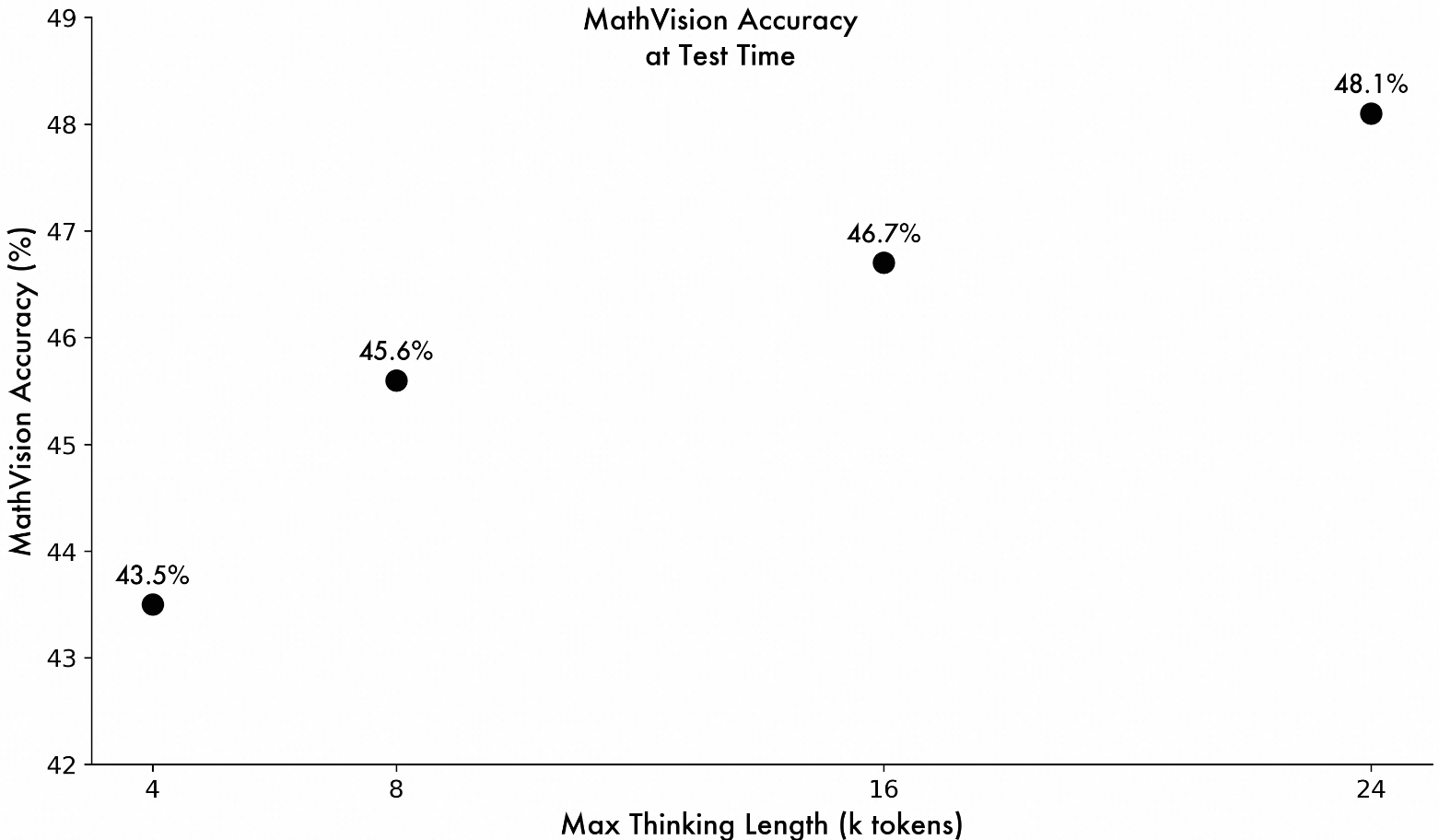
MathVision is a benchmark that aggregates various challenging multimodal mathematical problems, and we evaluate a model’s ability to solve complex math problems based on its performance on this benchmark. As shown in the figure, by adjusting the maximum length of the model’s thinking process, we observe a continuous improvement in the model’s accuracy on MathVision, demonstrating the immense potential of the model.
In the following sections, we will discuss the design philosophy behind QVQ-Max, its actual capabilities, and what it can do for you.
Why Do We Need Visual Reasoning?
Traditional AI models mostly rely on text input, such as answering questions, writing articles, or generating code. However, in real life, much of the information isn’t expressed through words but rather through images, charts, or even videos. A single image can contain rich details like colors, shapes, spatial relationships, and more. These elements are often more intuitive, but also more complex than text.
For example, if you want to determine whether an architectural blueprint is reasonable, a description alone might not be enough. But if you could see the blueprint and analyze it using professional knowledge, the task becomes much easier. This is the significance of visual reasoning—it allows AI to not just “see,” but also “understand” and “think.”
Our goal in designing QVQ-Max was simple: to create an assistant that is both “sharp-eyed” and “quick-thinking,” capable of solving various practical problems for users.
Core Capabilities: From Observation to Reasoning
The capabilities of QVQ-Max can be summarized into three areas: detailed observation, deep reasoning, and flexible application. Let’s break down how it performs in each area.
Detailed Observation: Capturing Every Detail
QVQ-Max excels at parsing images, whether they’re complex charts or casual snapshots taken in daily life. It can quickly identify key elements in an image. For instance, it can tell you what objects are in a photo, what textual labels exist, and even point out small details that you might overlook.Deep Reasoning: Not Just “Seeing,” But Also “Thinking”
Identifying content in an image is not enough. QVQ-Max can further analyze this information and combine it with background knowledge to draw conclusions. For example, in a geometry problem, it can derive answers based on the accompanying diagram. In a video clip, it can predict what might happen next based on the current scene.Flexible Application: From Problem-Solving to Creation
Beyond analysis and reasoning, QVQ-Max can also perform interesting tasks like helping you design illustrations, generate short video scripts, or even create role-playing content based on your requirements. If you upload a rough sketch, it might help you refine it into a complete piece. Upload a regular photo, and it can transform into a sharp critic or even a fortune-teller.
Demo Cases
QVQ-Max has a wide range of applications, whether in learning, work, or daily life—it can come in handy in many scenarios.
Workplace Tool: At work, QVQ-Max can assist in completing data analysis, organizing information, and even writing code
Learning Assistant: For students, QVQ-Max can help solve difficult problems in subjects like math and physics, especially those accompanied by diagrams. It can also explain complex concepts in an intuitive way, making learning easier.
Life Helper: In daily life, QVQ-Max can offer practical advice. For instance, it can recommend outfit combinations based on photos of your wardrobe, or guide you through cooking a new dish based on recipe images.
Next Step
The current version of QVQ-Max is just the first iteration, and there’s still much room for improvement. Moving forward, we will focus on several key areas:
- More Accurate Observations: Enhance recognition accuracy through grounding techniques, which validate observations made from visual content.
- Visual Agent: Improve the model’s ability to handle multi-step and more complex tasks, such as operating smartphones or computers, and even playing games.
- Better Interaction: Expand beyond text-based interaction to include more modalities, such as tool verification and visual generation, allowing for richer user experiences.
Overall, QVQ-Max is a visual reasoning model that possesses both “vision” and “intellect.” It doesn’t just recognize the content in images; it combines this information to analyze, reason, and even complete creative tasks. Although it’s still in its growth phase, it has already shown great potential. Through continuous optimization, we aim to make QVQ-Max a truly practical visual agent that helps everyone solve real-world problems.