At the end of January this year, we launched the Qwen2.5-VL series of models, which received widespread attention and positive feedback from the community. Building on the Qwen2.5-VL series, we continued to optimize the model using reinforcement learning and open-sourced the new VL model with the beloved 32B parameter scale under the Apache 2.0 license — Qwen2.5-VL-32B-Instruct. Compared to the previously released Qwen2.5-VL series models, the features of this 32B VL model are as follows:
Responses More Aligned with Human Preferences: Adjusted the output style to provide more detailed, better-formatted answers that align more closely with human preferences.
Mathematical Reasoning: Significant improvement in the accuracy of solving complex mathematical problems.
Fine-grained Image Understanding and Reasoning: Enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction.
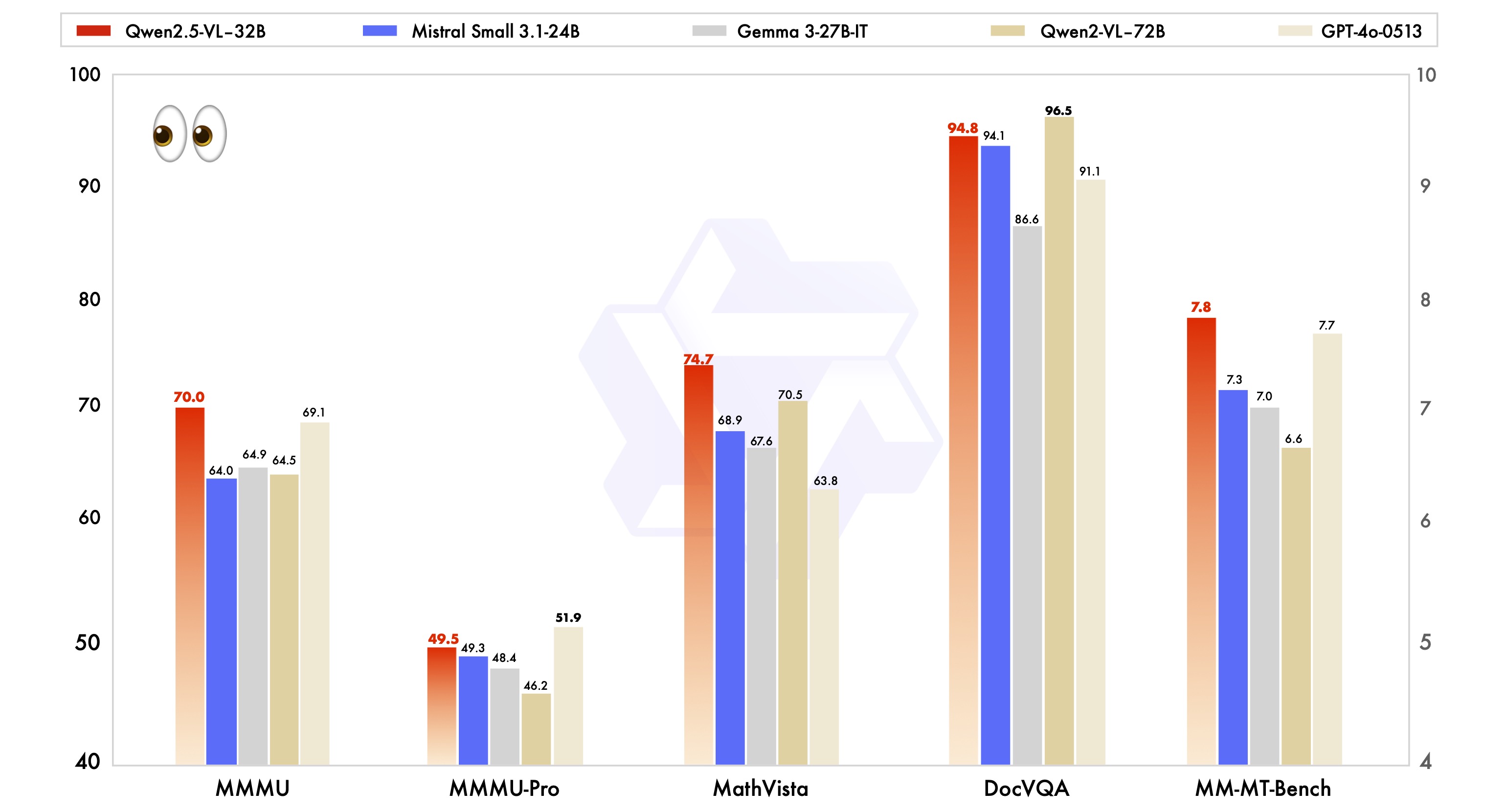
Extensive benchmarking against state-of-the-art (SoTA) models of comparable scale, Qwen2.5-VL-32B-Instruct has demonstrated superiority over baselines, e.g., Mistral-Small-3.1-24B and Gemma-3-27B-IT, even surpassing the larger Qwen2-VL-72B-Instruct. Notably, it achieves significant advantages in multimodal tasks such as MMMU, MMMU-Pro, and MathVista, which focus on complex, multi-step reasoning. On MM-MT-Bench, a benchmark emphasizing subjective user experience evaluation, Qwen2.5-VL-32B-Instruct outperforms its predecessor Qwen2-VL-72B-Instruct by a substantial margin.
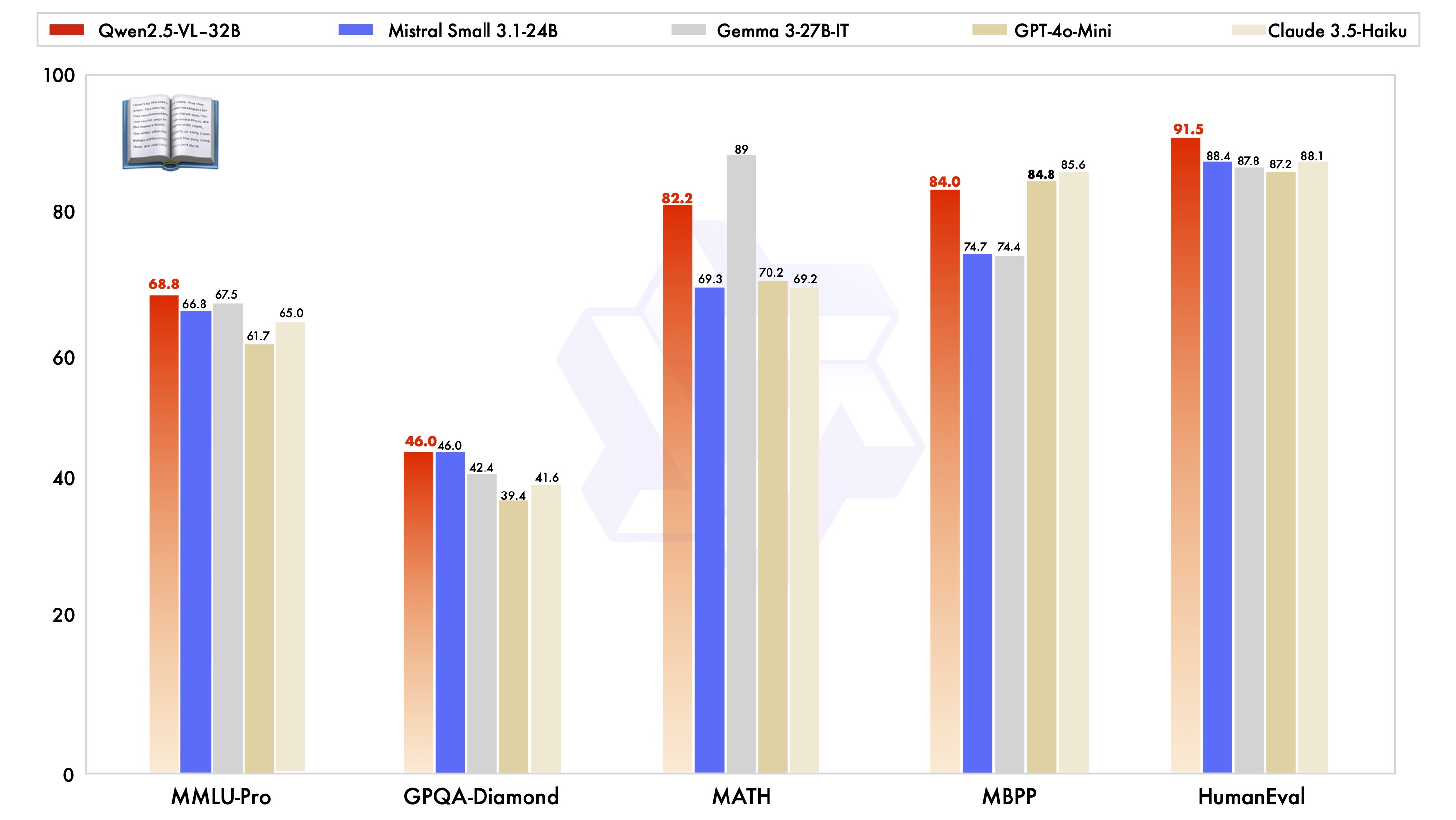
In addition to excelling in visual capabilities, Qwen2.5-VL-32B-Instruct has also achieved top-tier performance in pure text capabilities at the same scale.
If you start at 12:00 and it takes 1 hour and 6 minutes to travel 110 kilometers, your arrival time will be:
\[
12:00 + 1 \text{ hour and } 6 \text{ minutes} = 13:06
\]
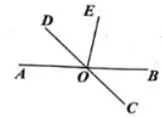
It is given that $ OD $ bisects $ \angle AOE $. This means:
$$
\angle AOD = \angle DOE.
$$
Since $ \angle AOD = 50^\circ $, we have:
$$
\angle DOE = 50^\circ.
$$
The angle $ \angle AOE $ is the sum of $ \angle AOD $ and $ \angle DOE $:
$$
\angle AOE = \angle AOD + \angle DOE = 50^\circ + 50^\circ = 100^\circ.
$$
Since $ AB $ is a straight line, the angles on a straight line sum up to $ 180^\circ $. Therefore:
$$
\angle AOE + \angle EOB = 180^\circ.
$$
Substituting $ \angle AOE = 100^\circ $, we get:
$$
100^\circ + \angle EOB = 180^\circ.
$$
Solving for $ \angle EOB $:
$$
\angle EOB = 180^\circ - 100^\circ = 80^\circ.
$$
While Qwen2.5-VL-32B has focused on optimizing subjective experience and mathematical reasoning through reinforcement learning—operating within the paradigm of “fast thinking”. Our next research direction will prioritize long and effective reasoning processes to push the boundaries of visual models in tackling highly complex, multi-step visual reasoning tasks.
If you find our model helpful, feel free to cite it:
@article{Qwen2.5-VL,
title={Qwen2.5-VL Technical Report},
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
journal={arXiv preprint arXiv:2502.13923},
year={2025}
}