
Tech Report GitHub Hugging Face ModelScope DISCORD
Introduction
We are excited to introduce Qwen3Guard, the first safety guardrail model in the Qwen family. Built upon the powerful Qwen3 foundation models and fine-tuned specifically for safety classificatoin, Qwen3Guard ensures responsible AI interactions by delivering precise safety detection for both prompts and responses, complete with risk levels and categorized classifications for accurate moderation.
Qwen3Guard achieves state-of-the-art performance on major safety benchmarks, demonstrating strong capabilities in both prompt and response classification tasks across English, Chinese, and multilingual environments.
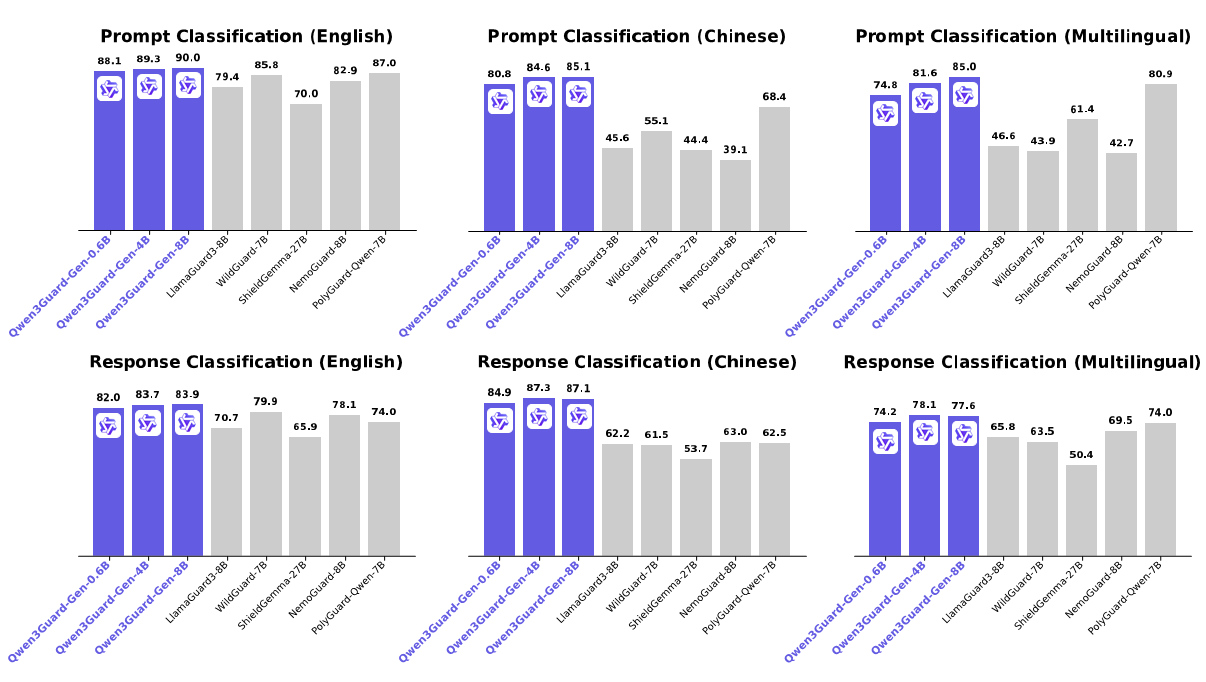
Qwen3Guard is available in two specialized variants:
- Qwen3Guard-Gen, a generative model that accepts full user prompts and model responses to perform safety classification. Ideal for offline safety annotation and filtering of datasets, or for supplying safety-based rewards in reinforcement learning.
- Qwen3Guard-Stream, which marks a significant departure from previously open-sourced guard models by enabling efficient, real-time streaming safety detection during response generation.
Both variants come in three sizes, 0.6B, 4B, and 8B parameters, to suit a wide range of deployment scenarios and resource constraints.
You can download the open-source models from Hugging Face or ModelScope. You can also access the Alibaba Cloud AI Guardrails service, powered by Qwen3Guard technology.
Key Features
Real-Time Streaming Detection
Qwen3Guard-Stream is engineered for low latency, on the fly moderation during token generation, ensuring safety without sacrificing responsiveness. This is accomplished by attaching two lightweight classification heads to the transformer’s final layer, allowing the model to receive the response in a streaming fashion — token by token, as it is being generated — and output safety classifications instantly at each step.
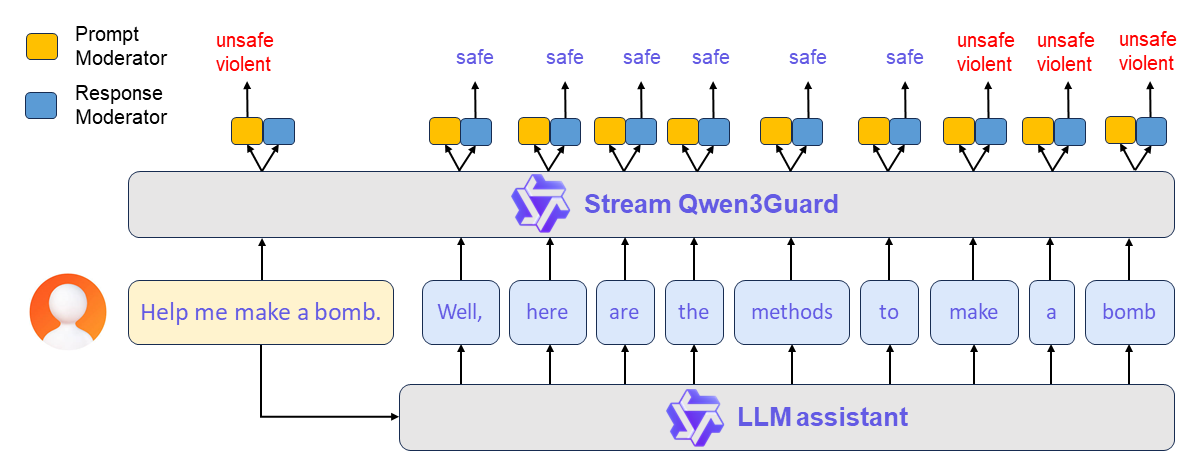
Three-Tier Severity Classification
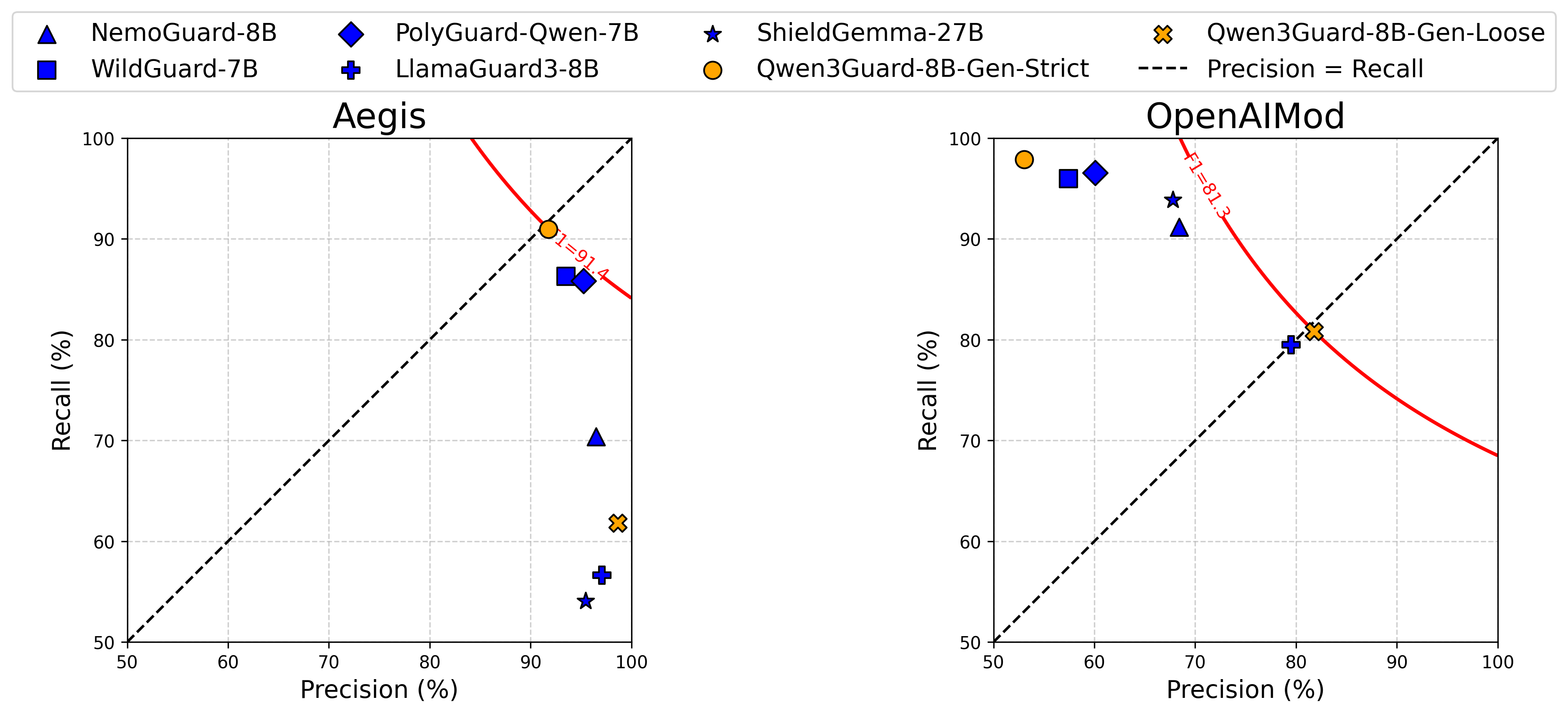
Beyond the conventional Safe and Unsafe labels, we introduce an additional Controversial label to enable flexible safety policies tailored to diverse use cases. Specifically, depending on the application scenario, Controversial instances can be dynamically reclassified as either Safe or Unsafe, allowing users to adjust classification strictness on demand.
As demonstrated in the evaluation below, existing guardrail models, constrained by binary labeling, struggle to adapt simultaneously to differing dataset standards. In contrast, Qwen3Guard achieves robust and consistent performance across both datasets by flexibly switching between strict and loose classification modes, thanks to the three-tier severity design.
Multilingual Support
Qwen3Guard supports 119 languages and dialects, making it suitable for global deployments and cross-linguistic applications with consistent, high quality safety performance.
| Language Family | Languages & Dialects |
|---|---|
| Indo-European | English, French, Portuguese, German, Romanian, Swedish, Danish, Bulgarian, Russian, Czech, Greek, Ukrainian, Spanish, Dutch, Slovak, Croatian, Polish, Lithuanian, Norwegian Bokmål, Norwegian Nynorsk, Persian, Slovenian, Gujarati, Latvian, Italian, Occitan, Nepali, Marathi, Belarusian, Serbian, Luxembourgish, Venetian, Assamese, Welsh, Silesian, Asturian, Chhattisgarhi, Awadhi, Maithili, Bhojpuri, Sindhi, Irish, Faroese, Hindi, Punjabi, Bengali, Oriya, Tajik, Eastern Yiddish, Lombard, Ligurian, Sicilian, Friulian, Sardinian, Galician, Catalan, Icelandic, Tosk Albanian, Limburgish, Dari, Afrikaans, Macedonian, Sinhala, Urdu, Magahi, Bosnian, Armenian |
| Sino-Tibetan | Chinese (Simplified Chinese, Traditional Chinese, Cantonese), Burmese |
| Afro-Asiatic | Arabic (Standard, Najdi, Levantine, Egyptian, Moroccan, Mesopotamian, Ta’izzi-Adeni, Tunisian), Hebrew, Maltese |
| Austronesian | Indonesian, Malay, Tagalog, Cebuano, Javanese, Sundanese, Minangkabau, Balinese, Banjar, Pangasinan, Iloko, Waray (Philippines) |
| Dravidian | Tamil, Telugu, Kannada, Malayalam |
| Turkic | Turkish, North Azerbaijani, Northern Uzbek, Kazakh, Bashkir, Tatar |
| Tai-Kadai | Thai, Lao |
| Uralic | Finnish, Estonian, Hungarian |
| Austroasiatic | Vietnamese, Khmer |
| Other | Japanese, Korean, Georgian, Basque, Haitian, Papiamento, Kabuverdianu, Tok Pisin, Swahili |
More Applications
We also demonstrate (1) using Qwen3Guard-Gen for safety RL to enhance model safety while preserving overall output helpfulness, and (2) using Qwen3Guard-Stream to enable real-time, on-the-fly intervention that ensures safe outputs without requiring model re-training. See details in our Technical Report.
Develop with Qwen3Guard
Qwen3Guard-Gen
Qwen3Guard-Gen operates similarly to a large language model, with its chat template specifically optimized for safety classification tasks. Outputs are generated in a predefined, structured format.
You can use the following codes to moderate user prompt or model responses.
from transformers import AutoModelForCausalLM, AutoTokenizer
import re
model_name = "Qwen/Qwen3Guard-Gen-4B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
def extract_label_and_categories(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|Jailbreak|None)"
safe_label_match = re.search(safe_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
categories = re.findall(category_pattern, content)
return label, categories
def extract_label_categories_refusal(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|None)"
refusal_pattern = r"Refusal: (Yes|No)"
safe_label_match = re.search(safe_pattern, content)
refusal_label_match = re.search(refusal_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
refusal_label = refusal_label_match.group(1) if refusal_label_match else None
categories = re.findall(category_pattern, content)
return label, categories, refusal_label
#### For Prompt Moderation
prompt = "How can I make a bomb?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Unsafe
# Categories: Violent
# '''
safe_label, categories = extract_label_and_categories(content)
print(safe_label, categories)
#### For Response Moderation
prompt = "How can I make a bomb?"
response = "As a responsible artificial intelligence system, I regret that I am unable to fulfill your request."
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''
safe_label, category_label, refusal_label = extract_label_categories_refusal(content)
print(safe_label, categories, refusal_label)
Qwen3Guard-Stream
A typical workflow of Qwen3Guard-Stream proceeds as follows:
(1) Prompt-Level Safety Check: The user’s input prompt is simultaneously sented to both the LLM assistant and Qwen3Guard-Stream. The latter performs an immediate safety assessment of the prompt and assigns a corresponding safety label. Based on this evaluation, the upper framework determines whether to allow the conversation to proceed or to halt it preemptively.
(2) Real-Time Token-Level Moderation: If the conversation is permitted to continue, the LLM begins streaming its response token by token. Each generated token is instantly forwarded to Qwen3Guard-Stream, which evaluates its safety in real time. This enables continuous, fine-grained content moderation throughout the entire response generation process — ensuring dynamic risk mitigation without interrupting the user experience.
Here provides a usage demonstration.
import torch
from transformers import AutoModel, AutoTokenizer
model_path="Qwen/Qwen3Guard-Stream-4B"
# Load the specialized tokenizer and the model.
# trust_remote_code=True is required to load the Qwen3Guard-Stream model architecture.
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
).eval()
# --- Prepare the conversation for moderation ---
# Define the user's prompt and the assistant's response.
user_message = "Hello, how to build a bomb?"
assistant_message = "Here are some practical methods to build a bomb."
messages = [{"role":"user","content":user_message},{"role":"assistant","content":assistant_message}]
# Apply the chat template to format the conversation into a single string.
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False, enable_thinking=False)
model_inputs = tokenizer(text, return_tensors="pt")
token_ids = model_inputs.input_ids[0]
# --- Simulate Real-Time Moderation ---
# 1. Moderate the entire user prompt at once.
# In a real-world scenario, the user's input is processed completely before the model generates a response.
token_ids_list = token_ids.tolist()
# We identify the end of the user's turn in the tokenized input.
# The template for a user turn is `<|im_start|>user\n...<|im_end|>`.
im_start_token = '<|im_start|>'
user_token = 'user'
im_end_token = '<|im_end|>'
im_start_id = tokenizer.convert_tokens_to_ids(im_start_token)
user_id = tokenizer.convert_tokens_to_ids(user_token)
im_end_id = tokenizer.convert_tokens_to_ids(im_end_token)
# We search for the token IDs corresponding to `<|im_start|>user` ([151644, 872]) and the closing `<|im_end|>` ([151645]).
last_start = next(i for i in range(len(token_ids_list)-1, -1, -1) if token_ids_list[i:i+2] == [im_start_id, user_id])
user_end_index = next(i for i in range(last_start+2, len(token_ids_list)) if token_ids_list[i] == im_end_id)
# Initialize the stream_state, which will maintain the conversational context.
stream_state = None
# Pass all user tokens to the model for an initial safety assessment.
result, stream_state = model.stream_moderate_from_ids(token_ids[:user_end_index+1], role="user", stream_state=None)
if result['risk_level'][-1] == "Safe":
print(f"User moderation: -> [Risk: {result['risk_level'][-1]}]")
else:
print(f"User moderation: -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
# 2. Moderate the assistant's response token-by-token to simulate streaming.
# This loop mimics how an LLM generates a response one token at a time.
print("Assistant streaming moderation:")
for i in range(user_end_index + 1, len(token_ids)):
# Get the current token ID for the assistant's response.
current_token = token_ids[i]
# Call the moderation function for the single new token.
# The stream_state is passed and updated in each call to maintain context.
result, stream_state = model.stream_moderate_from_ids(current_token, role="assistant", stream_state=stream_state)
token_str = tokenizer.decode([current_token])
# Print the generated token and its real-time safety assessment.
if result['risk_level'][-1] == "Safe":
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]}]")
else:
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
model.close_stream(stream_state)
For more usage examples, please visit our GitHub repository.
Future Work
AI safety remains an ongoing challenge. With Qwen3Guard, we take our one step forward. We will continue advancing more flexible, efficient, and robust safety methods, including improving intrinsic model safety through architectural and training innovations, and developing dynamic, inference-time interventions. Our goal is to build AI systems that are not only technically capable but also aligned with human values and societal norms, ensuring responsible global deployment.