Qwen Code Hebdomadaire : Limite de Tokens doublée, Affichage en temps réel, Support éditeur JetBrains
Cette semaine, nous avons publié la version fonctionnelle v0.12.4 et 2 versions de correctifs, ainsi que la version preview v0.13.0-preview.
Vous voulez essayer les nouvelles fonctionnalités preview ? Exécutez npm i @qwen-code/qwen-code@v0.13.0-preview.1 -g pour installer.
Après le lancement de v0.12.0, nous avons reçu beaucoup de retours utilisateurs. Cette semaine, nous nous sommes concentrés sur la résolution des problèmes affectant l’expérience utilisateur : problèmes d’encodage de sortie chinoise Windows, perte de sortie shell interactive, et erreurs de retry API. Côté fonctionnalités, nous avons apporté des améliorations complètes sur les tokens : limite doublée à 16K, affichage en temps réel de la consommation, et nouvelle commande /context pour les détails. Nous avons également ajouté le support des éditeurs JetBrains et Zed.
✨ Nouvelles Fonctionnalités
Limite de Tokens doublée : Lire plus de contexte, obtenir plus d’informations
La limite de tokens de sortie a été augmentée de 8K à 16K, permettant à l’IA de lire plus de contexte et de générer des réponses plus complètes. Elle détecte également automatiquement le paramètre max_tokens du modèle, pas besoin de configuration manuelle.
Cas d’utilisation :
- L’IA peut lire plus de contenu de fichiers et comprendre des structures de projet plus vastes
- Générer du code et des documents plus complets sans assembler des segments
- S’adapter automatiquement aux limites de tokens des différents modèles sans craindre les dépassements
Affichage en temps réel de la consommation de tokens (Preview)
Pendant la réflexion et la génération de l’IA, l’interface affiche la consommation de tokens en temps réel. Pas besoin d’attendre la fin de la conversation - connaissez votre consommation à tout moment.
Cas d’utilisation :
- Voir la consommation de tokens en temps réel pendant les conversations
- Ajuster rapidement quand la consommation est anormale pour éviter le gaspillage
- Comparer les coûts en tokens de différentes tâches pour optimiser l’utilisation
Voir PR #2445
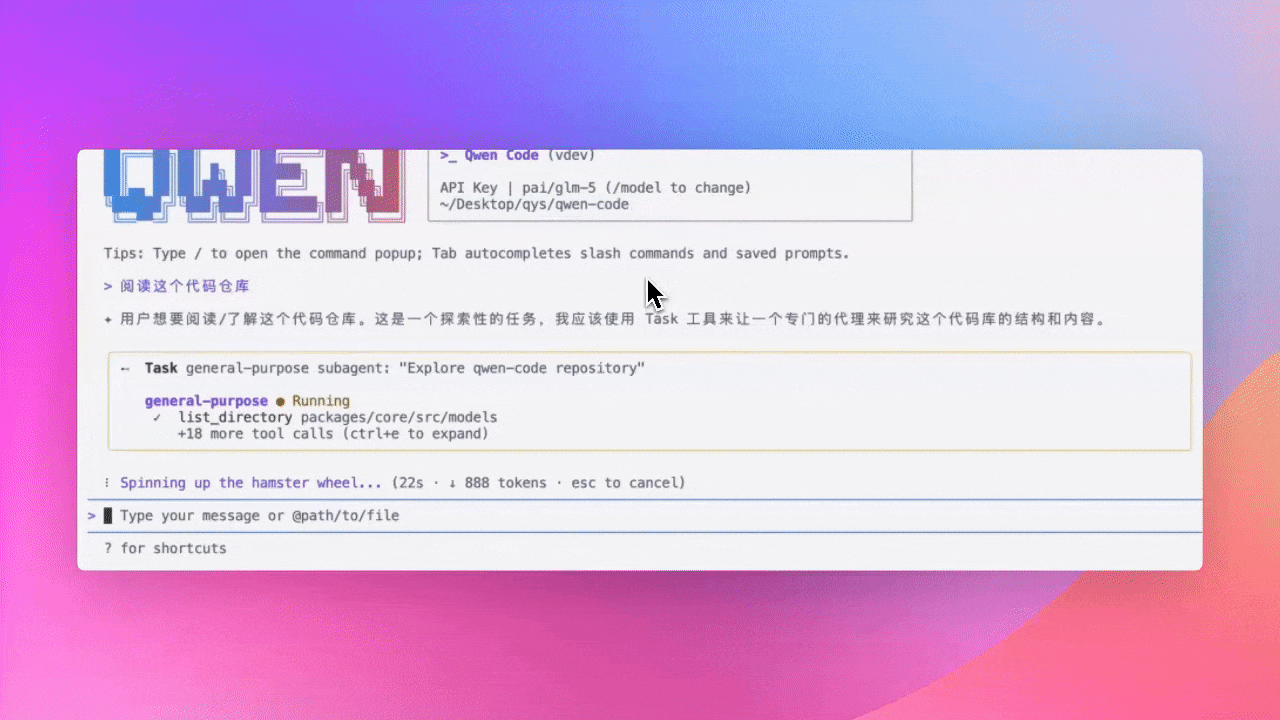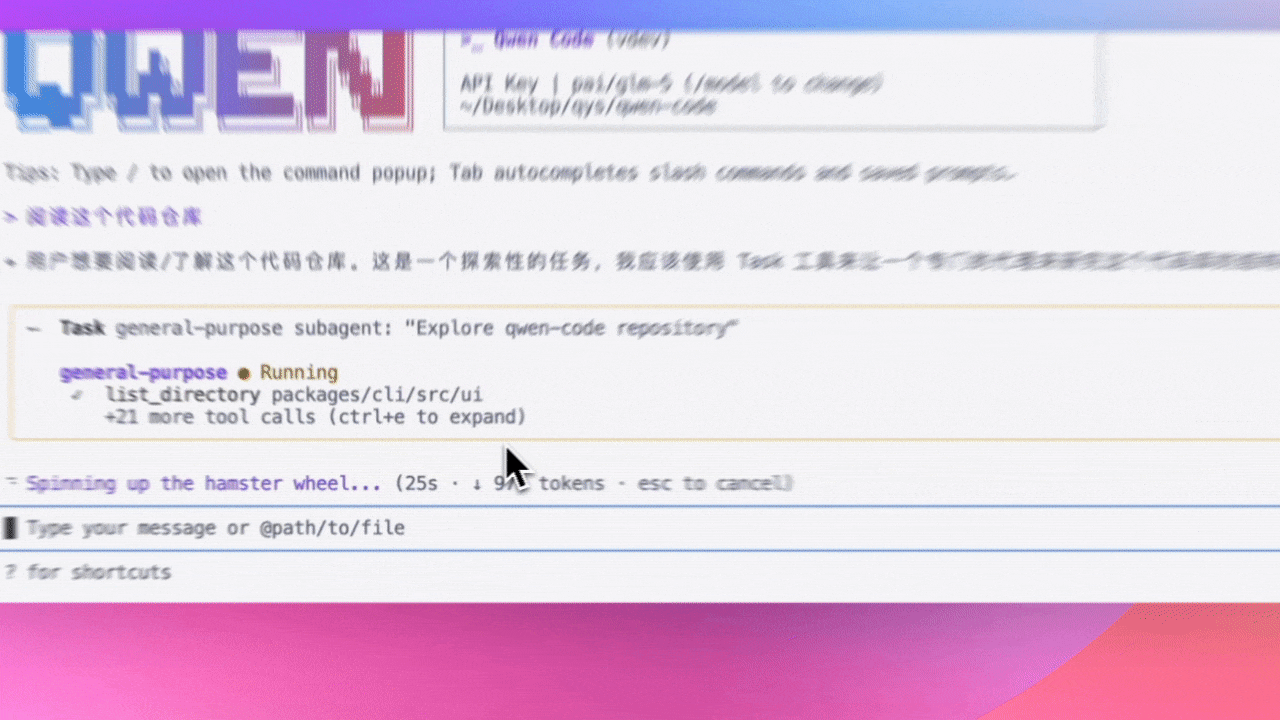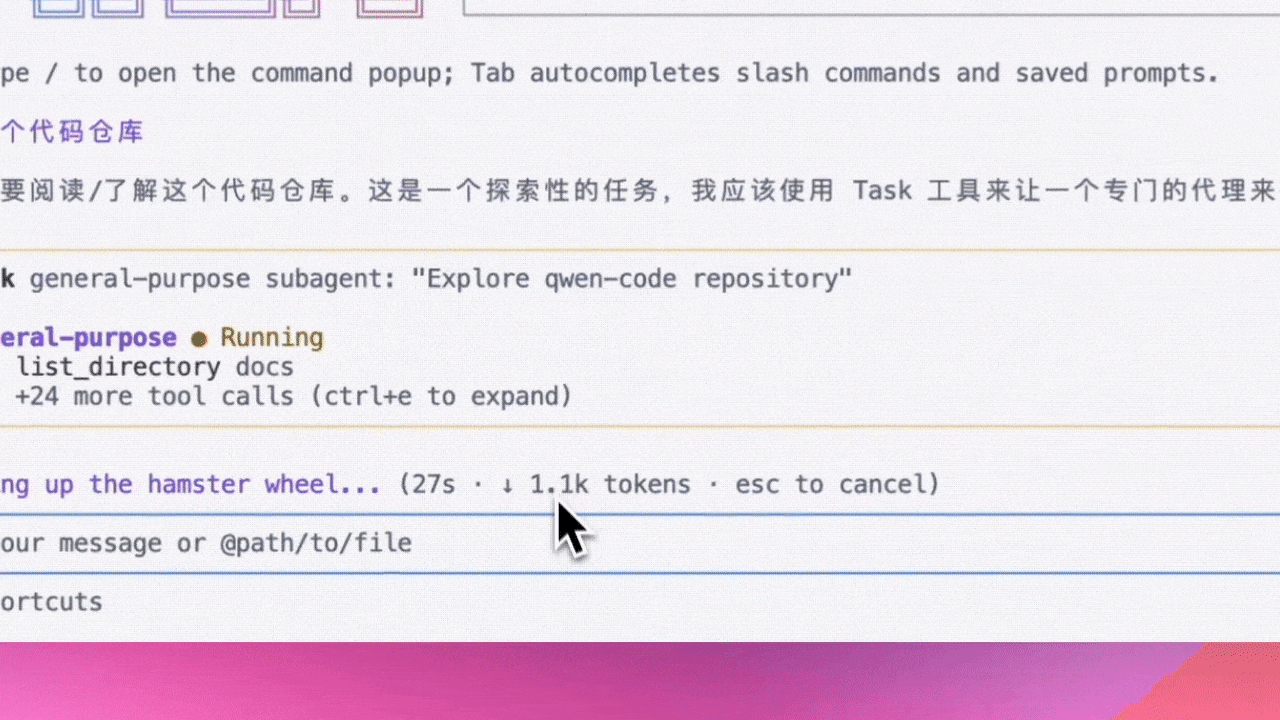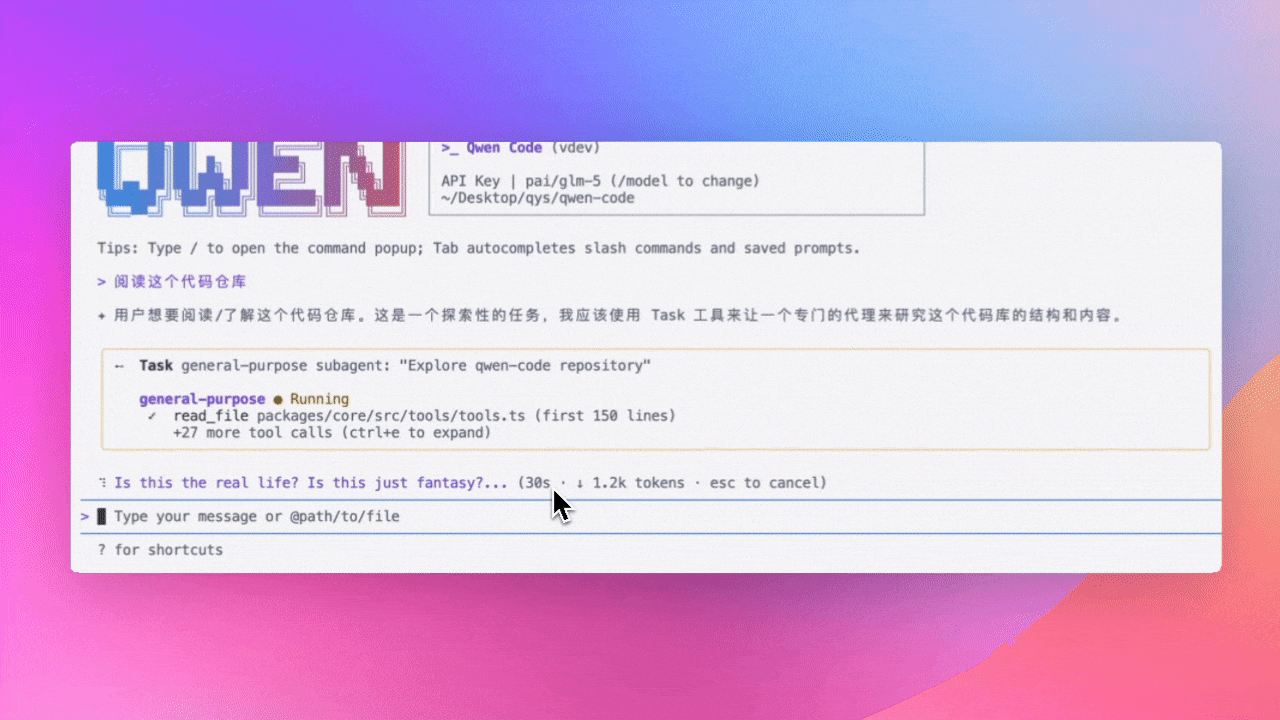
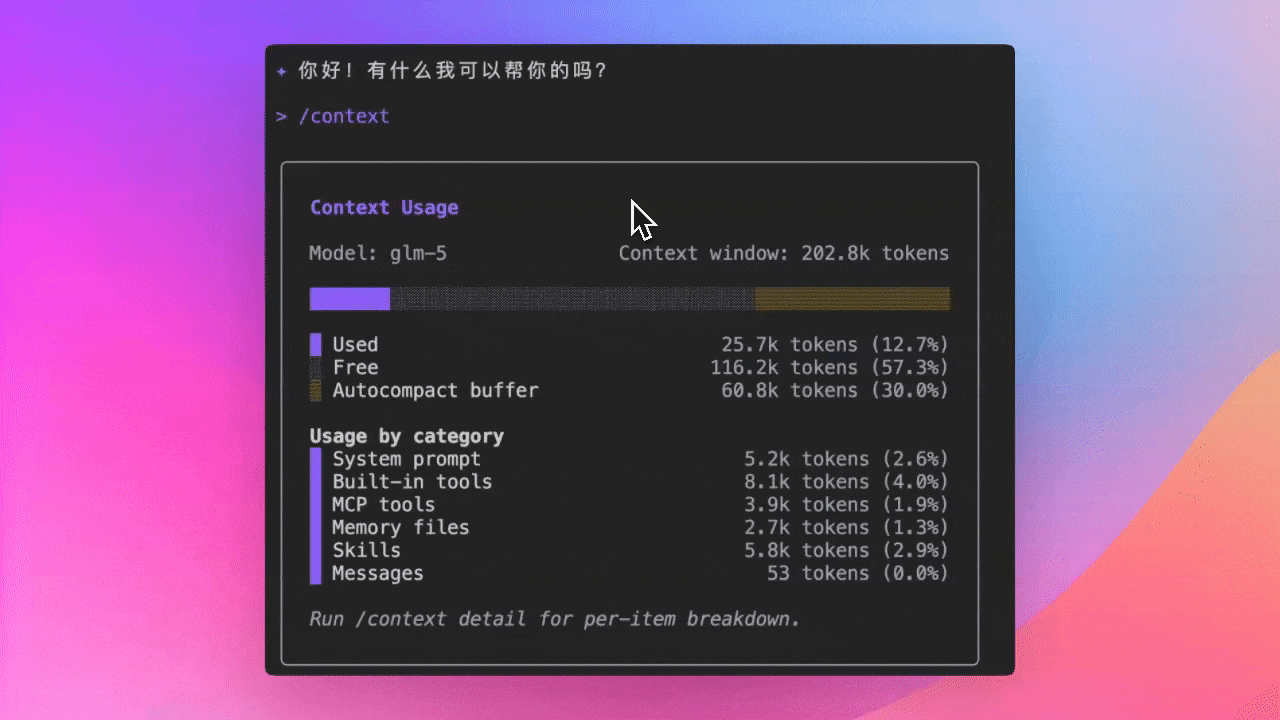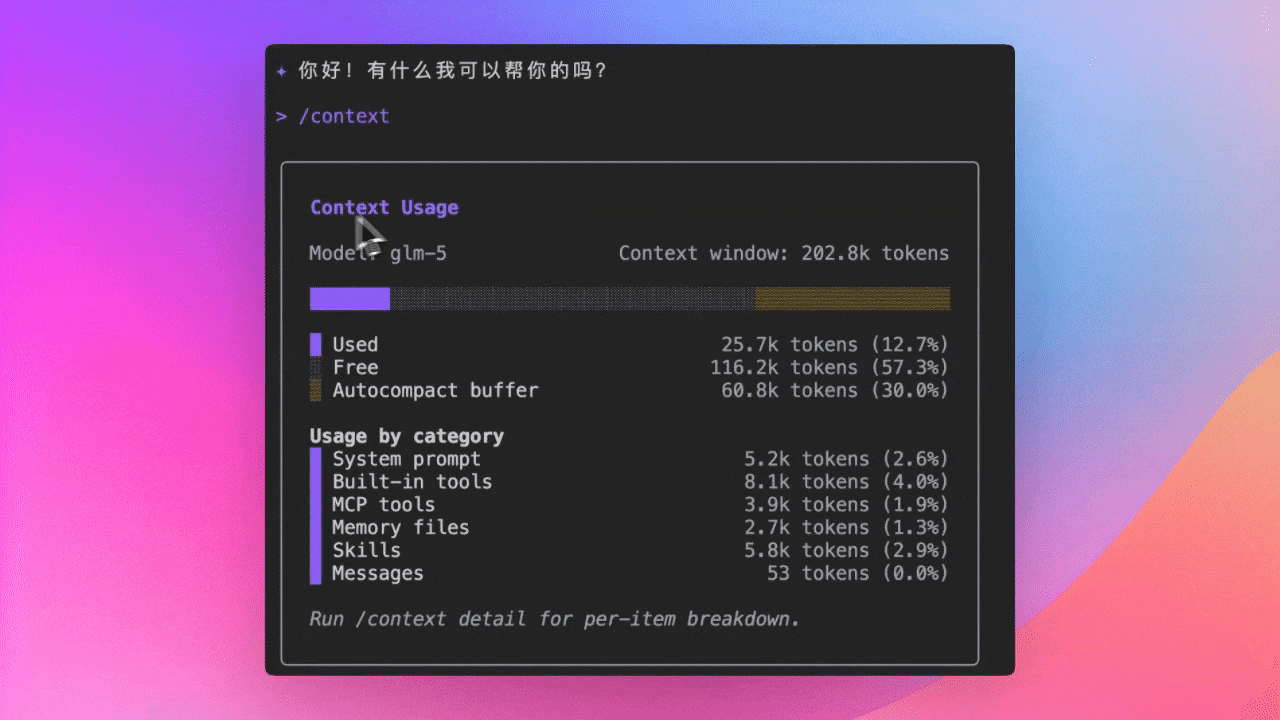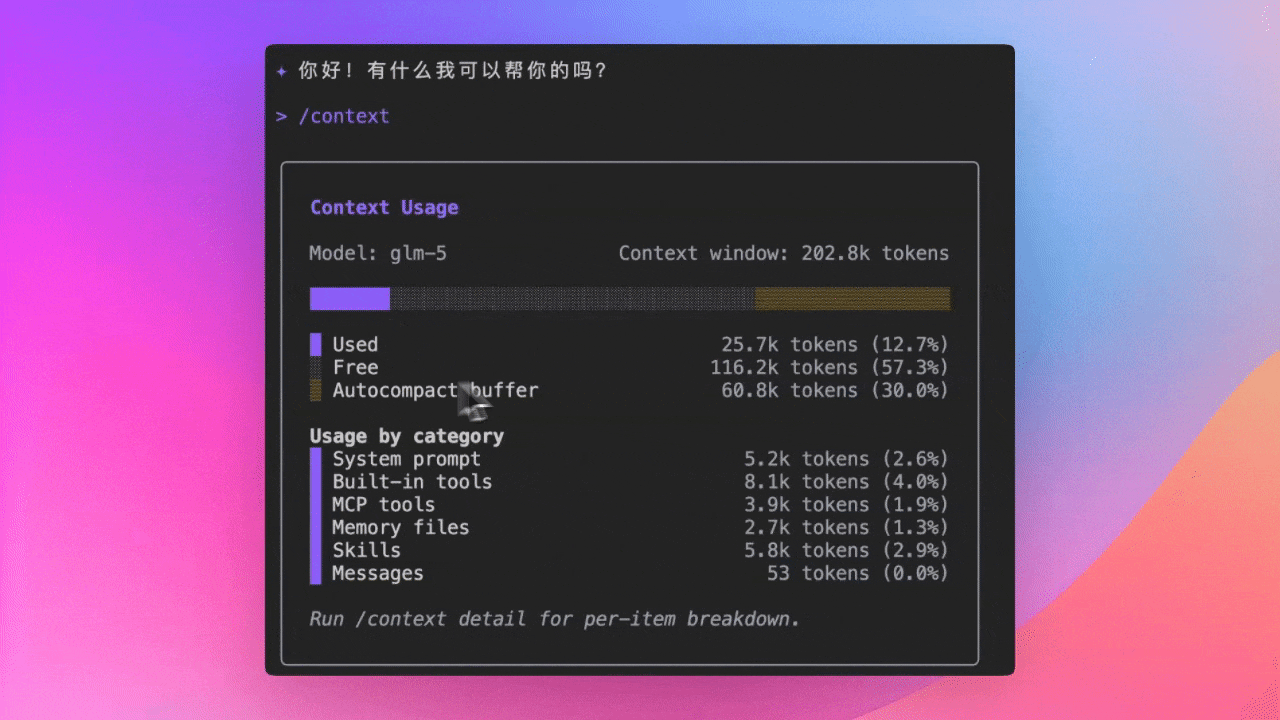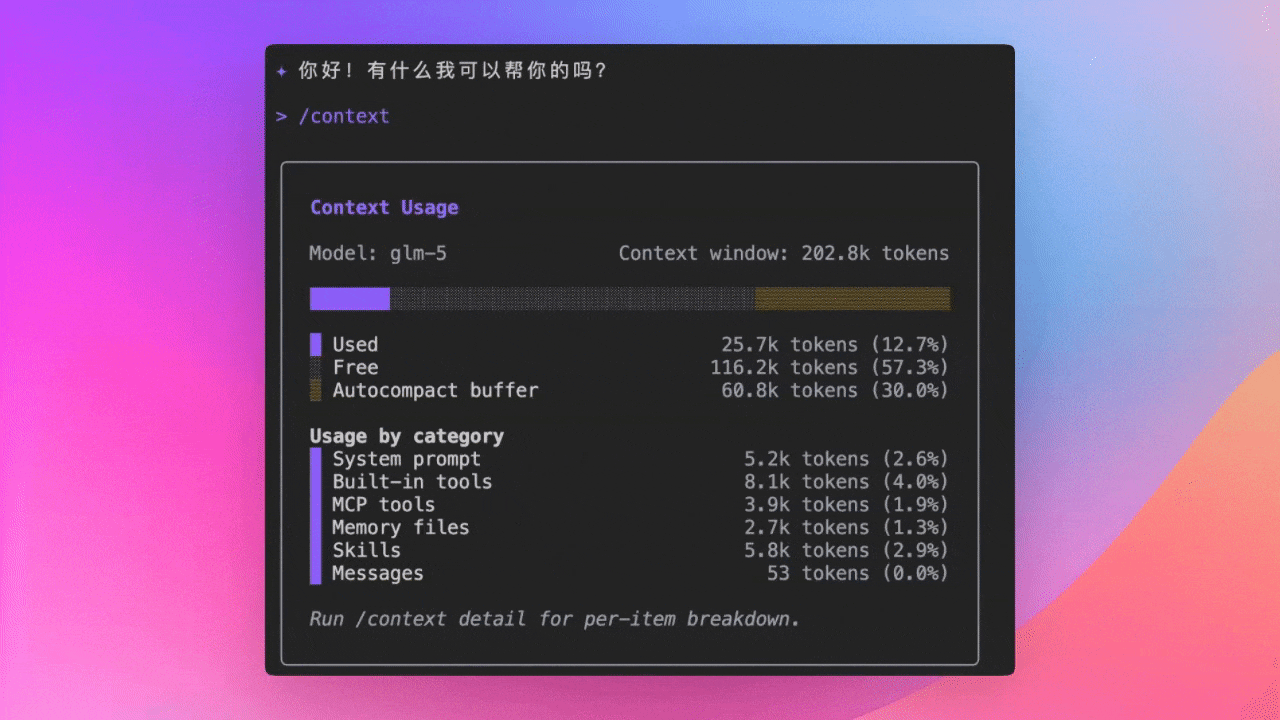
Commande /context : Voir les détails de consommation de tokens (Preview)
Utilisez la commande /context pour voir les détails de consommation de tokens dans la fenêtre de contexte : quels fichiers utilisent combien de tokens, combien d’espace reste - tout d’un coup d’œil.
Cas d’utilisation :
- Voir la consommation de tokens de la conversation actuelle, savoir combien de contenu peut encore être ajouté
- Découvrir quels fichiers utilisent trop de tokens et décider si un nettoyage est nécessaire
- Optimiser l’utilisation du contexte pour garder l’IA concentrée sur le contenu clé
Voir PR #1835
Intégration éditeurs Zed et JetBrains
En plus de VS Code, Qwen Code supporte maintenant Zed et la série d’éditeurs JetBrains (IntelliJ IDEA, PyCharm, WebStorm, etc.). Voir PR #2372 .
Cas d’utilisation :
- Utiliser Qwen Code directement dans les IDE JetBrains sans changer de fenêtre
- Les utilisateurs de l’éditeur Zed peuvent également profiter de l’assistant de codage IA
- Expérience unifiée entre différents éditeurs, pas besoin de réadaptation
Documentation :
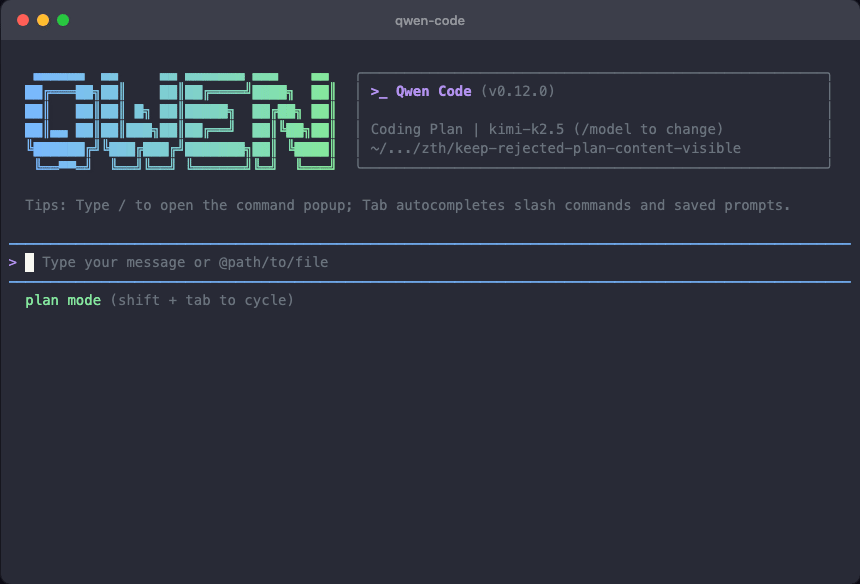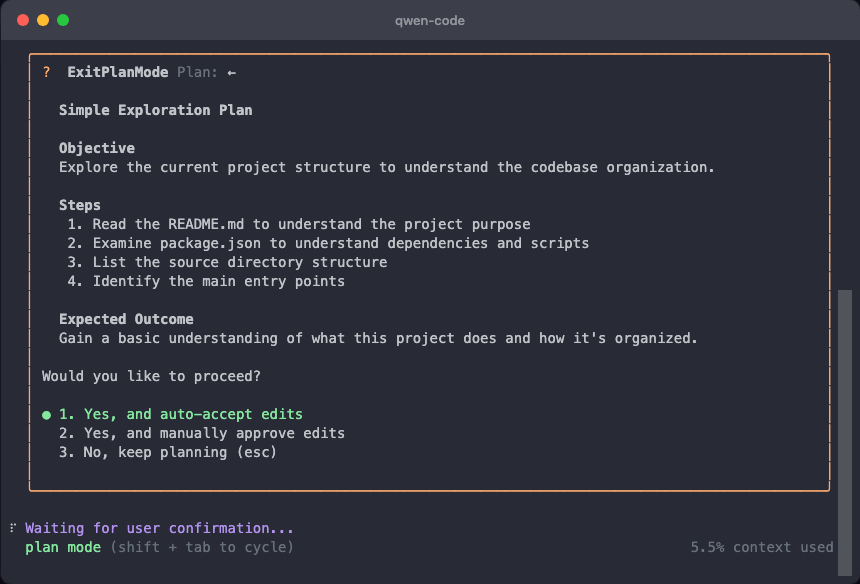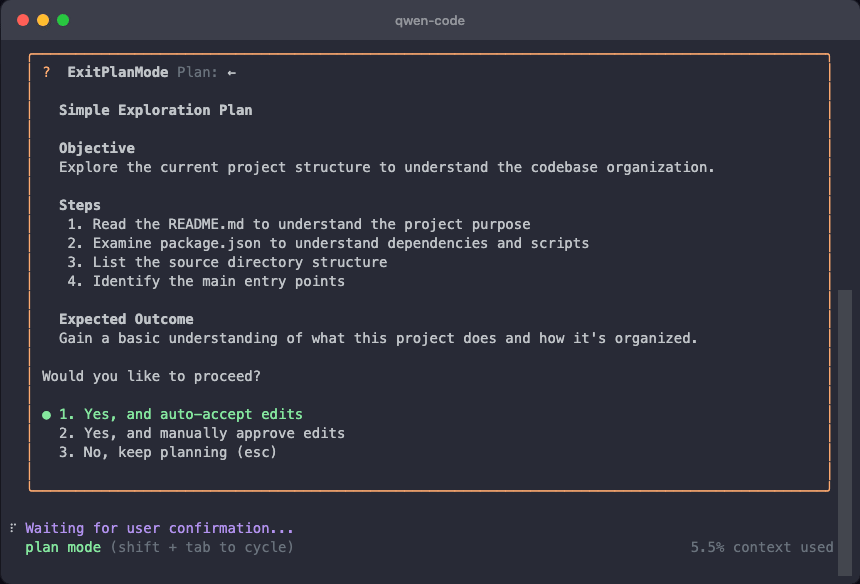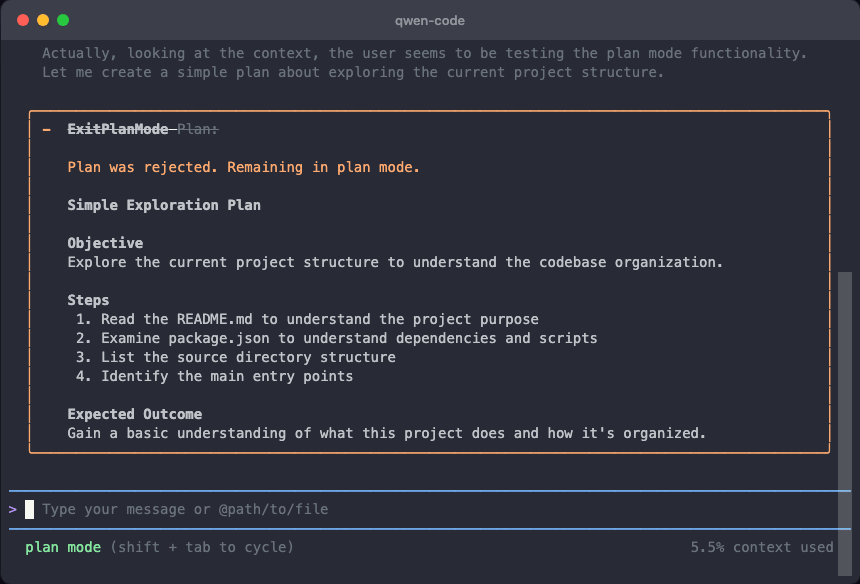
Plan Mode : Les propositions rejetées sont maintenant visibles
En Plan Mode, quand une proposition de l’IA est rejetée par vous, le contenu ne disparaît pas. Vous pouvez comparer différentes propositions et choisir la plus appropriée.
Cas d’utilisation :
- Comparer plusieurs propositions de l’IA et choisir la meilleure solution
- Revoir le contenu précédent après rejet sans demander à l’IA de régénérer
- Comparaison de propositions plus intuitive pour des décisions plus sereines
Voir PR #2157
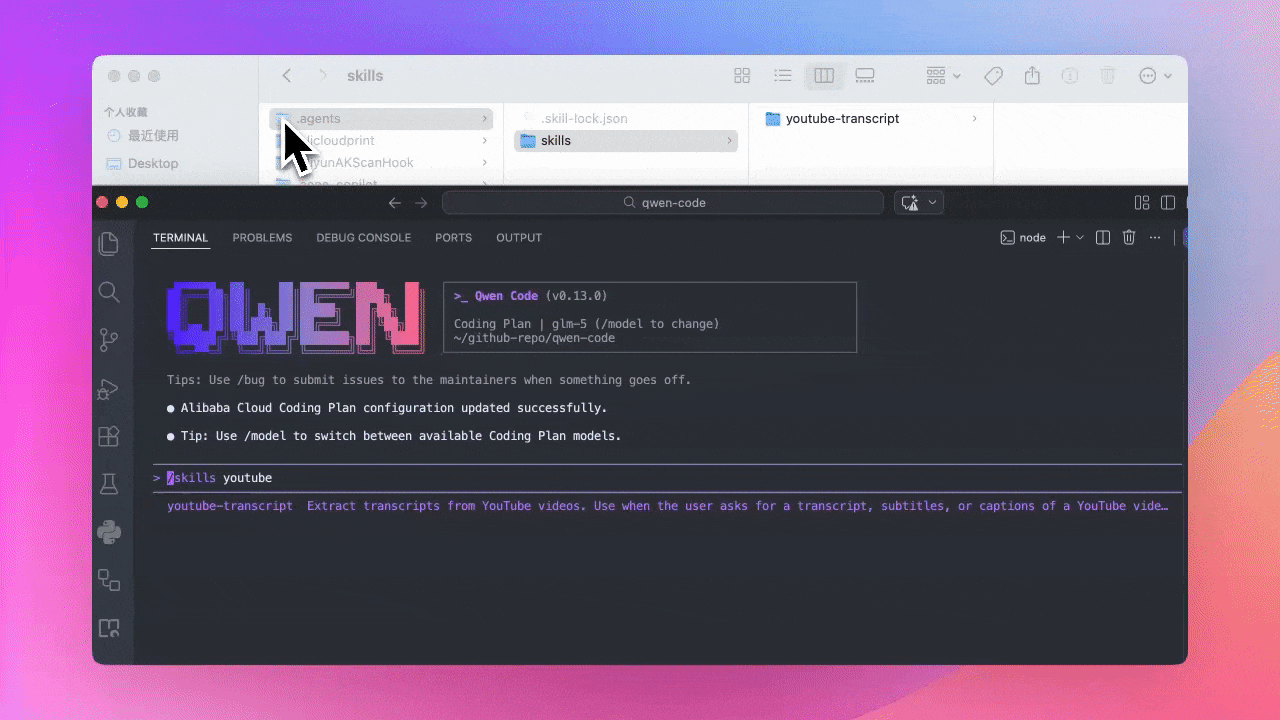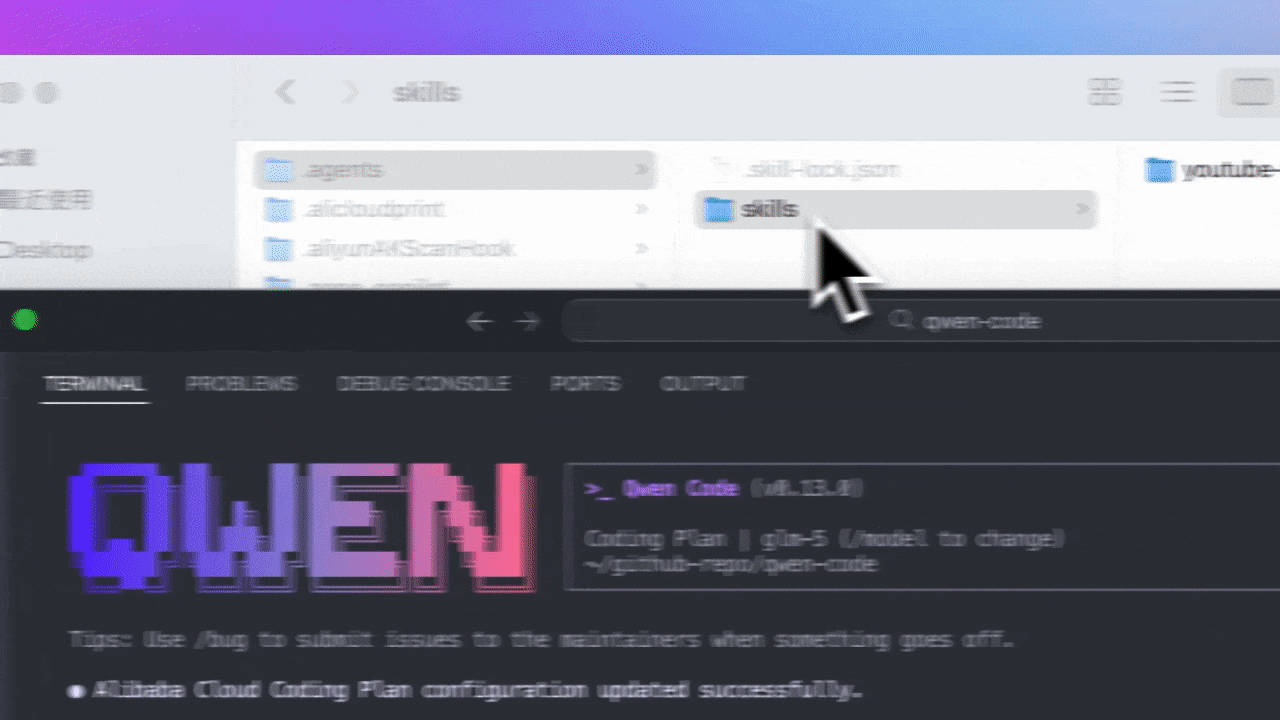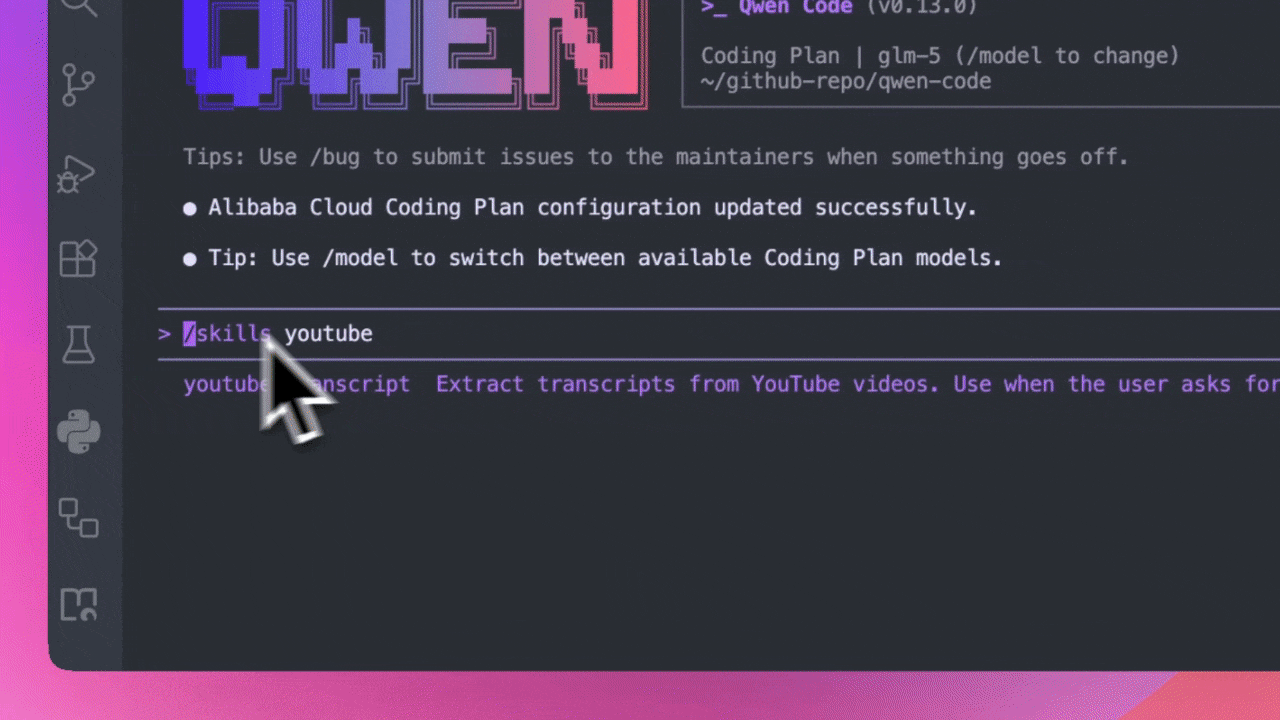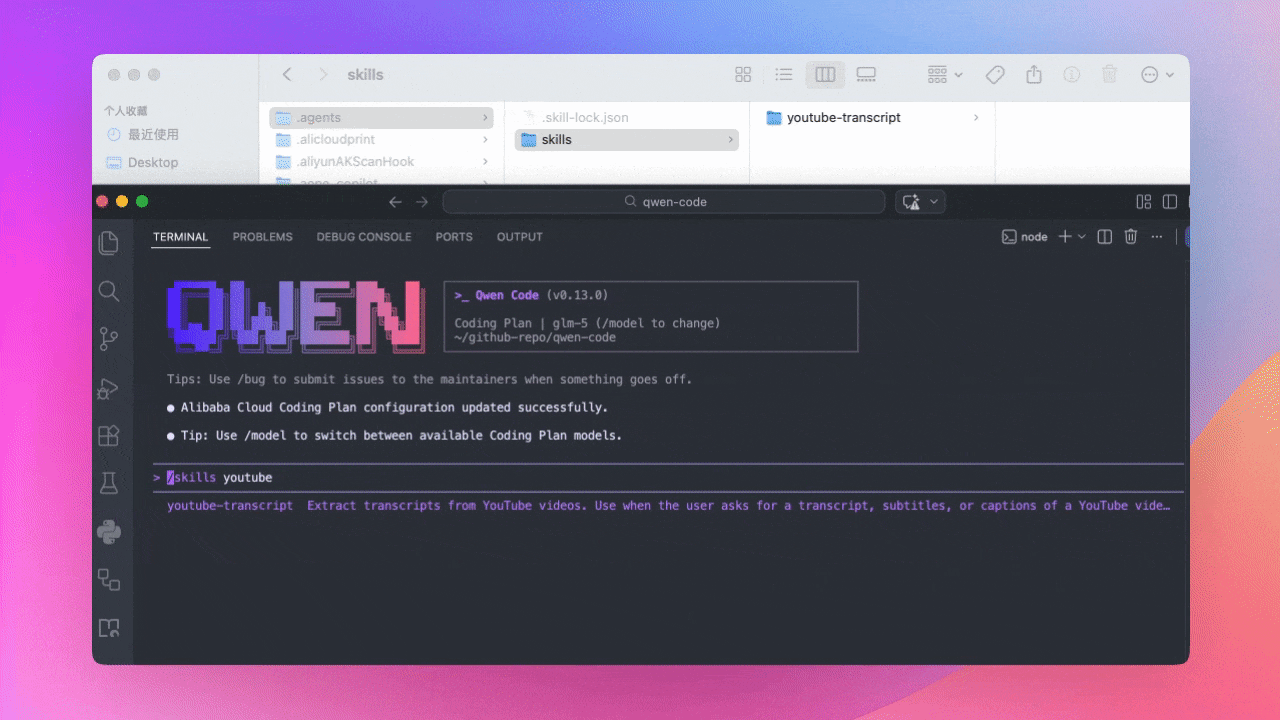
Support du répertoire .agents (Preview)
Les fichiers de compétences peuvent maintenant être placés dans le répertoire .agents du projet, gérés ensemble avec le code du projet. Les membres de l’équipe peuvent utiliser la même configuration de compétences après avoir cloné le projet.
Cas d’utilisation :
- Placer les compétences liées au projet dans le répertoire
.agentspour un contrôle de version avec le code - Les membres de l’équipe partagent la configuration sans configuration manuelle individuelle
- Différents projets peuvent avoir des configurations indépendantes sans interférence
Voir PR #2202
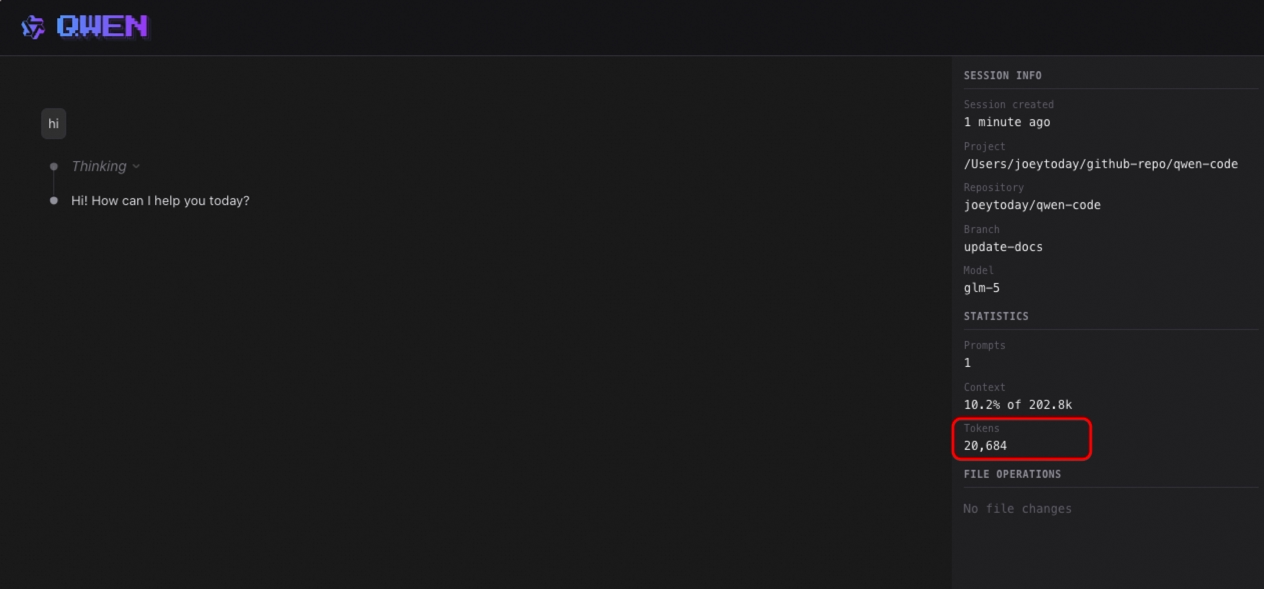
Export de session avec métadonnées et statistiques (Preview)
Lors de l’export de sessions, les métadonnées et statistiques sont maintenant incluses : temps de conversation, consommation de tokens, nombre de messages, etc. Pratique pour l’archivage et l’analyse d’utilisation.
Cas d’utilisation :
- Enregistrer automatiquement le temps de conversation et la consommation de tokens lors de l’export pour un suivi facile
- Analyser statistiquement les habitudes d’utilisation
- Archiver les conversations importantes avec des informations complètes
Voir PR #2328
📊 Améliorations
- La sortie shell n’inonde plus l’écran : Les grandes sorties sont automatiquement tronquées, la sortie des outils est plus concise, pas de ralentissement dû aux sorties longues (#2388 )
- Localisation des descriptions de commandes slash : Les descriptions de
/helpet autres commandes supportent l’affichage multilingue (#2333 )
🔧 Correctifs Importants
| PR | Version | Correctif | Impact |
|---|---|---|---|
| #2423 | v0.12.5 | Correction du problème d’encodage de sortie non-ASCII Windows | Les sorties chinoises, japonaises et autres non-anglaises ne sont plus illisibles sous Windows |
| #2438 | v0.12.6 | Amélioration de la gestion max_tokens avec des valeurs par défaut conservatrices | Évite les erreurs de certains modèles dues à un max_tokens excessif |
| #2024 | v0.12.4 | Rejet des fichiers PDF pour éviter la corruption de session | L’ouverture de PDF ne cause plus de problèmes de session |
| #2389 | v0.12.4 | Correction de la perte de sortie shell interactive rapide | La sortie des commandes ne perd plus de contenu |
| #2367 | v0.12.4 | Correction des erreurs de retry API | Plus d’erreurs API mystérieuses |
| #2280 | v0.12.4 | Correction de la définition de type JSON Schema des Hooks | Plus d’erreurs de type lors de la configuration des Hooks |
Correctifs spécifiques à la plateforme Windows
| PR | Correctif | Impact |
|---|---|---|
| #2423 | Correction du problème d’encodage de sortie non-ASCII | Les sorties chinoises, japonaises et autres non-anglaises s’affichent correctement |
| #2286 | Correction de l’échec d’installation d’extension | L’installation d’extension via git clone n’échoue plus sous Windows |
| #1904 | Normalisation de la variable d’environnement PATH Windows | Gestion plus stable des variables d’environnement lors de l’exécution shell |
Correctifs spécifiques à la plateforme macOS
| PR | Correctif | Impact |
|---|---|---|
| #2391 | Correction du problème de permission sandbox | L’accès aux périphériques terminal fonctionne correctement dans l’environnement sandbox macOS |
🎈 Autres Améliorations
- 7 nouveaux contributeurs : @netbrah , @chen893 , @hs-ye , @drewd789 , @Sakuranda , @kiri-chenchen , @ShihaoShenDev
- Ajout de la documentation sur le runtime Docker sandbox et l’utilisation Java (#1642 )
- Amélioration de la gestion des conditions de course pour l’annulation des prompts VS Code et le streaming (#2374 )
Comment mettre à niveau :
- Version stable :
npm i @qwen-code/qwen-code@latest -g - Version preview :
npm i @qwen-code/qwen-code@v0.13.0-preview.1 -g
Si vous avez des questions ou des suggestions, n’hésitez pas à nous faire part de vos retours sur GitHub Issues !