Mise en cache des tokens et optimisation des coûts
Qwen Code optimise automatiquement les coûts d’API grâce à la mise en cache des tokens lorsque vous utilisez l’authentification par clé API. Cette fonctionnalité stocke le contenu fréquemment utilisé, comme les instructions système et l’historique des conversations, afin de réduire le nombre de tokens traités dans les requêtes ultérieures.
Comment en bénéficier
- Réduction des coûts : moins de tokens signifie des coûts d’API réduits
- Réponses plus rapides : le contenu mis en cache est récupéré plus rapidement
- Optimisation automatique : aucune configuration nécessaire, tout se fait en arrière-plan
La mise en cache des tokens est disponible pour
- Les utilisateurs avec clé API (clé API Qwen, fournisseurs compatibles OpenAI)
Suivi de vos économies
Utilisez la commande /stats pour voir vos économies de tokens mis en cache :
- Lorsqu’elle est active, l’affichage des statistiques indique combien de tokens ont été servis depuis le cache
- Vous verrez à la fois le nombre absolu et le pourcentage de tokens mis en cache
- Exemple : « 10 500 (90,4 %) des tokens d’entrée ont été servis depuis le cache, ce qui réduit les coûts. »
Ces informations ne sont affichées que lorsque des tokens mis en cache sont utilisés, ce qui se produit avec l’authentification par clé API, mais pas avec l’authentification OAuth.
Exemple d’affichage des statistiques
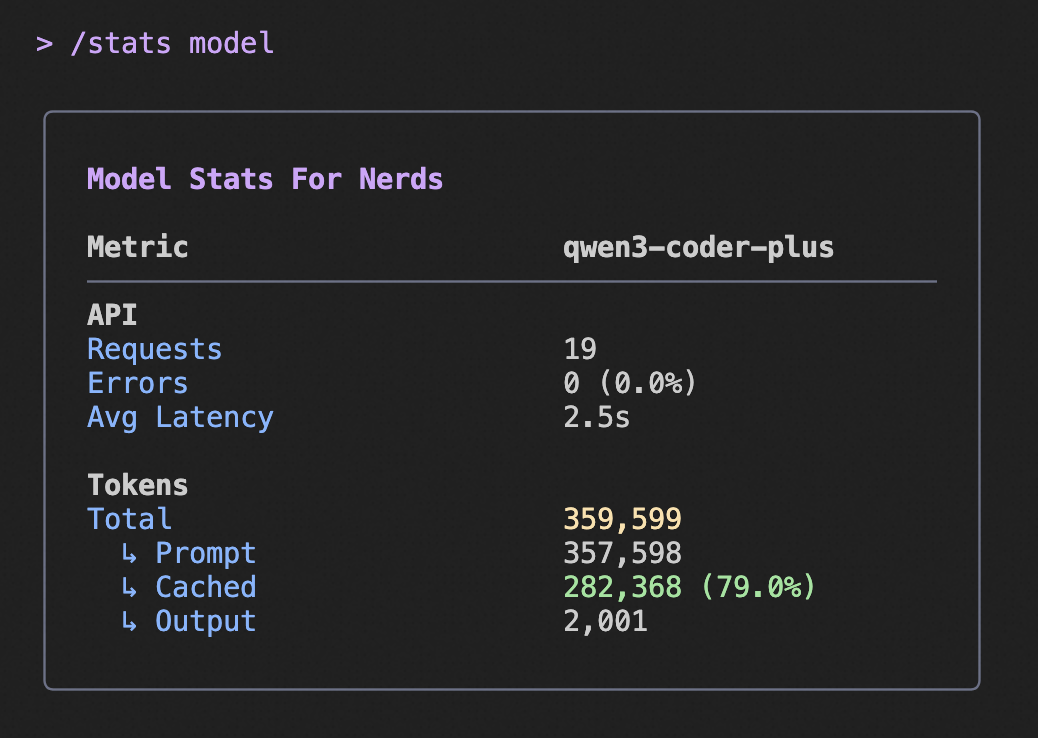
L’image ci-dessus montre un exemple de sortie de la commande /stats, mettant en évidence les informations sur les économies de tokens mis en cache.
Last updated on