Qwen Code Hebdo : DeepSeek V4 avec contexte d'un million de tokens, tâches en arrière-plan unifiées et conversations réversibles
Cette semaine, nous avons publié v0.15.7 comme version principale, ainsi que six mises à jour intermédiaires (v0.15.1-v0.15.6).
DeepSeek V4 a beaucoup fait parler de lui dans la communauté IA cette semaine. Pendant que le moteur d’inférence local d’antirez circulait sur HN et que les fournisseurs ajoutaient leur support, nous avons aussi livré l’intégration côté Qwen Code : contexte 1M, limite de sortie 384K, reasoning effort “max” et correctifs pour les thinking blocks.
Le multitâche des agents s’impose progressivement dans les outils de développement, notamment avec OpenAI Codex et Google AlphaEvolve. Dans Qwen Code, cela se traduit maintenant par un vrai panneau de tâches : vous voyez les tâches en arrière-plan au même endroit, vous pouvez les annuler, et les reprendre après une interruption. GitHub vient aussi de publier des recommandations pour les revues de PR par agents ; dans le même esprit, nous avons étendu qwen review avec davantage de sous-commandes et d’agents pour exécuter une revue complète depuis le terminal.
Nous avons également réduit les petites frictions du quotidien. Si une conversation part dans la mauvaise direction, deux pressions sur Esc suffisent pour revenir à un tour précédent. Quand une tâche longue se termine ou demande une autorisation, Terminal et VS Code peuvent vous prévenir. /stats estime les coûts une fois les prix configurés, et le changement de modèle se fait désormais en une commande.
✨ Nouvelles fonctionnalités
Prise en charge approfondie de DeepSeek V4
Après la sortie de DeepSeek V4, Qwen Code l’a pris en charge très rapidement. La fenêtre de contexte est fixée à 1M et la limite de sortie à 384K, ce qui permet à un Agent de lire de gros dépôts et de générer de longues réponses en une seule passe. Le niveau reasoning effort “max” est également disponible pour les tâches de raisonnement complexes. Plusieurs problèmes liés aux thinking blocks ont été corrigés afin que le raisonnement de DeepSeek reste visible dans les principaux workflows.
Ce que vous pouvez faire avec :
- Traiter de très gros fichiers et des dépôts entiers avec DeepSeek V4, sans craindre une coupure rapide du contexte 1M
- Régler reasoning effort sur “max” pour les conceptions d’architecture, les raisonnements longs et les tâches complexes
- Conserver le raisonnement de DeepSeek après restauration de session, retour arrière de conversation et compression de contexte
- Utiliser correctement les thinking blocks en mode compatible anthropic, y compris avec des déploiements tiers comme sglang ou vllm
Voir PR #3693 , #3800 , #3788 , #3747 , #3729
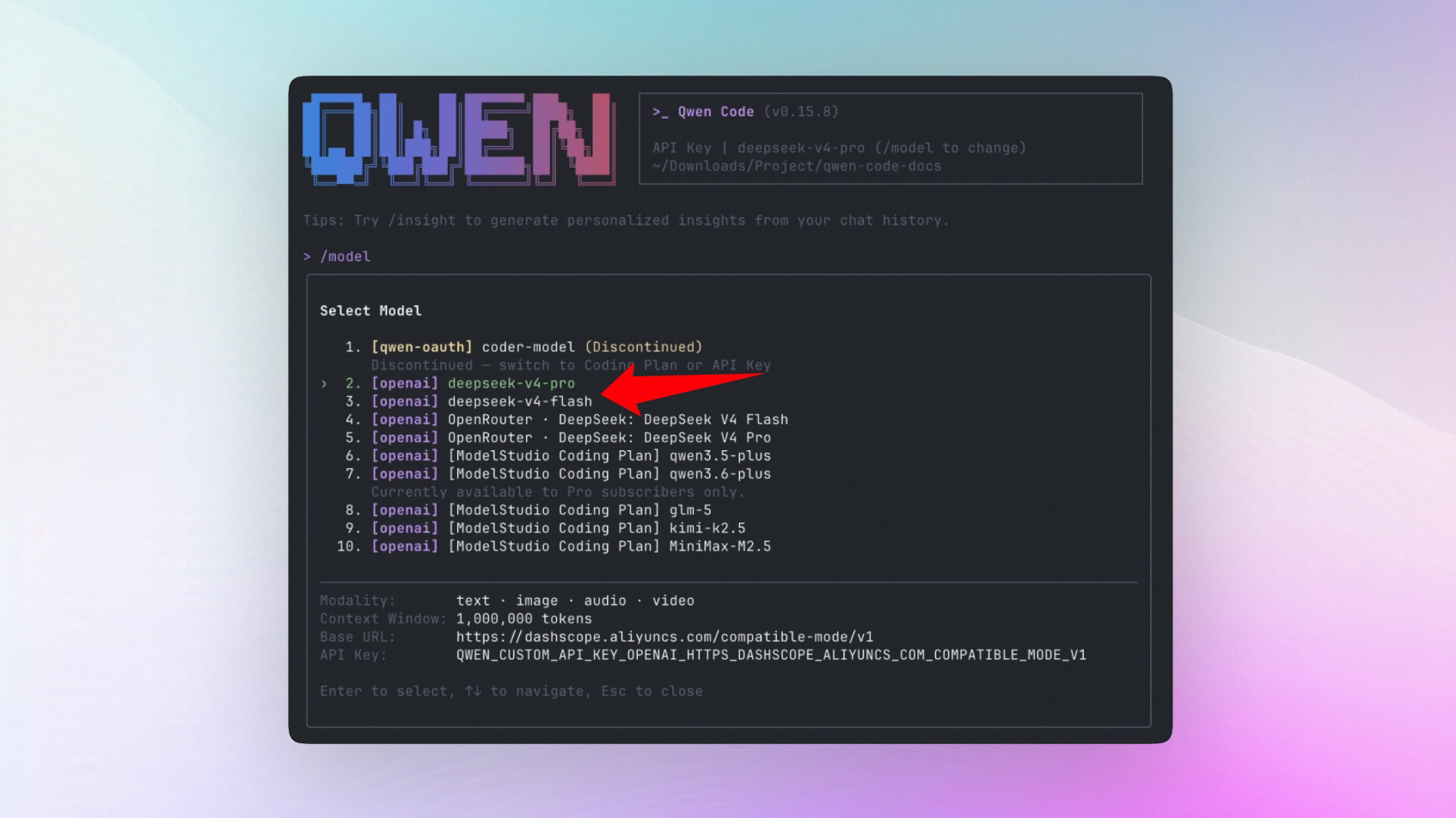
Voir, annuler et reprendre les tâches en arrière-plan
Auparavant, les commandes shell en arrière-plan étaient simplement déplacées hors du flux principal. Il était difficile de savoir si elles tournaient encore, où trouver la sortie, ou comment les arrêter. Désormais, les background agents et les shells en arrière-plan apparaissent dans une vue de tâches unifiée, avec statut, sortie et détails. Si une tâche est interrompue, elle se met automatiquement en pause et peut être reprise ou annulée.
Ce que vous pouvez faire avec :
- Lancer de longues tâches sans bloquer la conversation :
npm run dev, tests, watchers de fichiers et commandes similaires peuvent tourner en arrière-plan - Vérifier et contrôler l’état des tâches à tout moment via
/tasksou le panneau de tâches, y compris les chemins de sortie et l’annulation des tâches dont vous n’avez plus besoin - Reprendre après interruption sans perdre le travail : une tâche interrompue peut continuer ou être abandonnée
Revenir en arrière dans une conversation et repartir de là
Quand une conversation déviait, il fallait souvent corriger encore et encore, ou démarrer une nouvelle session. Vous pouvez maintenant appuyer deux fois sur Esc ou exécuter /rewind, choisir un tour utilisateur précédent et ramener l’historique à ce point pour repartir de la question initiale.
Ce que vous pouvez faire avec :
- Annuler une mauvaise direction : revenir à la question importante et relancer avec une consigne différente
- Réessayer sans perdre le contexte : pas besoin de nouvelle session ni de copier-coller les informations précédentes
- Explorer plus librement : revenir à un point de bifurcation quand vous testez plusieurs implémentations
Voir PR #3441
Flux de code review /review amélioré
/review a été entièrement revu. Le flux passe de 5 agents à 9 agents. Les étapes de revue auparavant dispersées dans le prompt sont déplacées dans 6 sous-commandes CLI multiplateformes, et la sortie devient du JSON structuré. Il suffit d’entrer /review <lien ou numéro de PR> pour que l’IA récupère le code, charge les règles du projet, lance le lint, effectue la revue parallèle, déduplique, vérifie la CI et publie les commentaires inline.
Ce que vous pouvez faire avec :
- Revoir une PR en une commande :
/review https://github.com/xxx/pull/123lance le flux complet - Faire relire par 9 rôles : en plus de la justesse et de la sécurité, les perspectives “attaquant”, “astreinte à 3 h du matin” et “mainteneur” aident à repérer plus d’angles morts
- Éviter d’approuver une CI rouge : l’état de CI et les self-PR sont détectés automatiquement, et un approve peut être rétrogradé en comment
- Garder les suggestions incertaines hors de la PR : les signalements à faible confiance restent dans le terminal
- Éviter les doublons : les commentaires Qwen existants sont reconnus
Voir PR #3754

Être prévenu quand une tâche se termine ou demande confirmation
Jusqu’ici, les rappels du terminal reposaient surtout sur un terminal bell peu visible. L’extension VS Code manquait elle aussi d’indicateurs assez clairs. Désormais, iTerm2, Kitty et Ghostty peuvent afficher une notification système à la fin d’une tâche ; VS Code utilise aussi un point sur l’onglet, des bulles de notification et un son.
Ce que vous pouvez faire avec :
- Ne plus surveiller le terminal pendant les longues tâches
- Repérer rapidement les demandes d’autorisation ou les questions de l’IA
- Ne pas rater de messages dans VS Code en travaillant dans d’autres fichiers
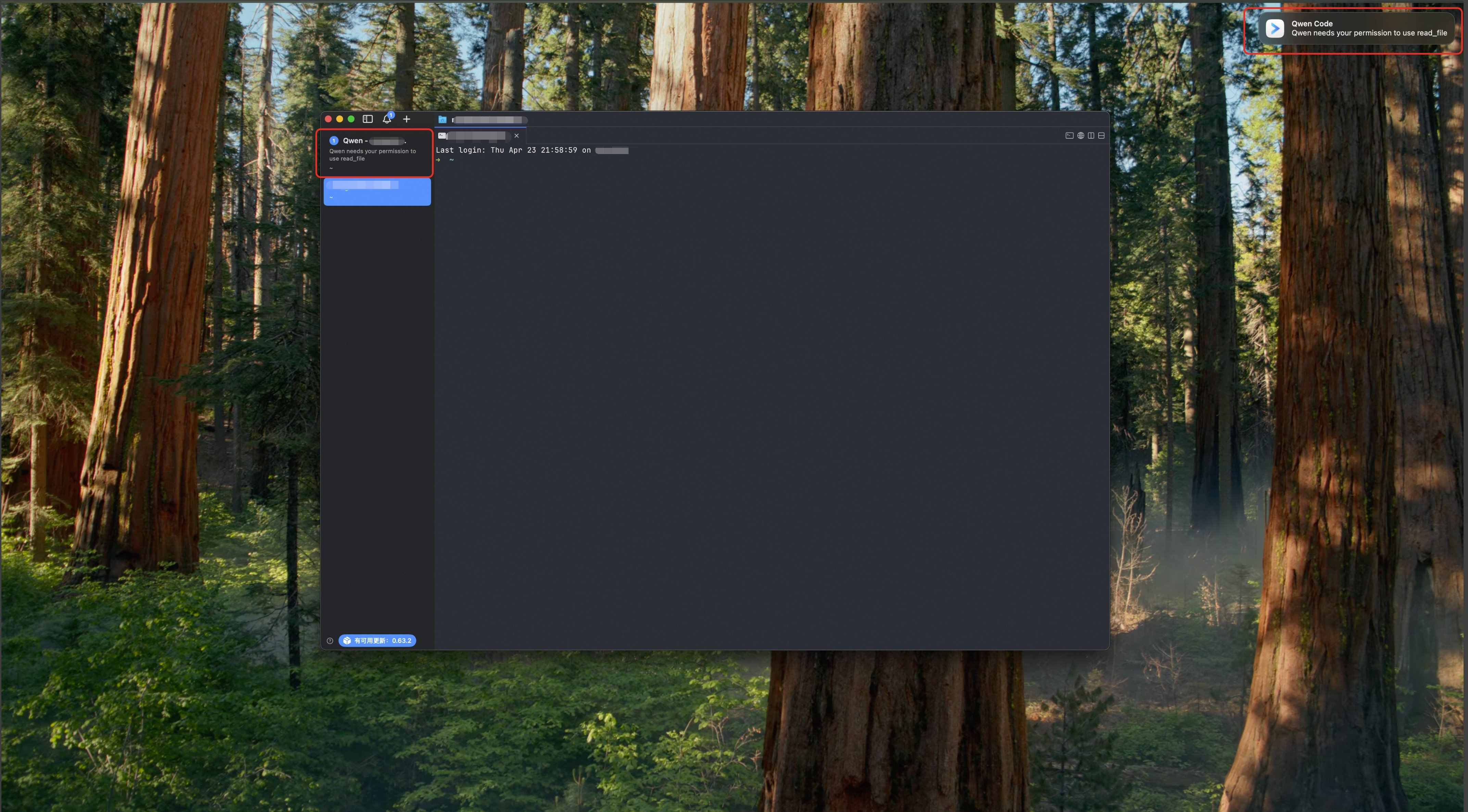
/stats affiche une estimation des coûts
La commande /stats ajoute l’estimation des coûts. Configurez modelPricing dans settings.json avec le prix d’entrée et de sortie par million de tokens, et /stats calculera une estimation à partir de la consommation. Sans configuration de prix, la commande continue simplement d’afficher les tokens comme avant.
Ce que vous pouvez faire avec :
- Configurer une fois les prix de vos modèles fréquents et laisser
/statsestimer les coûts - Comparer les coûts après un changement de modèle
- Surveiller les workflows longs et éviter les mauvaises surprises
Voir PR #3780
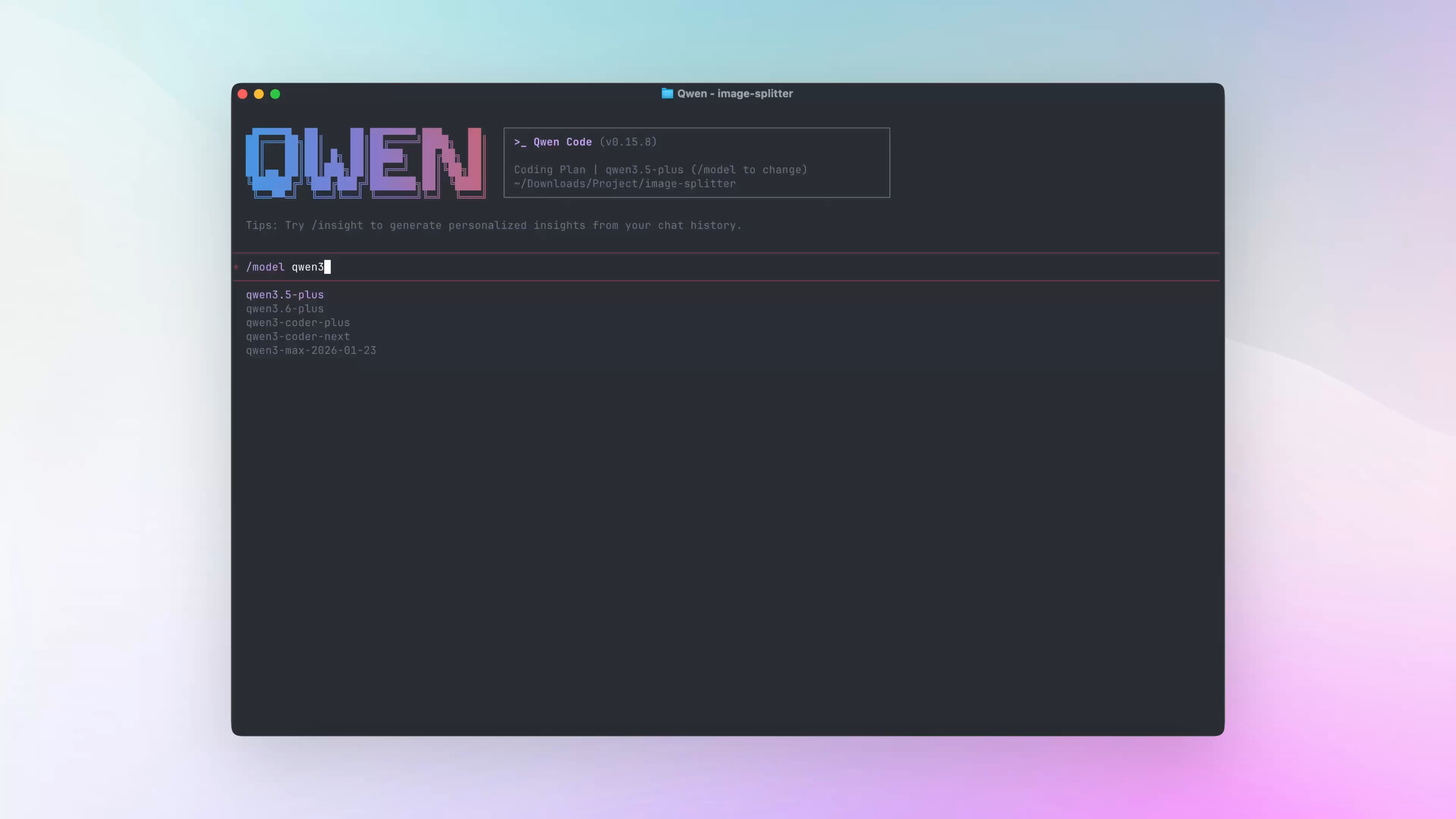
Changer rapidement de modèle avec /model
Avant, il fallait ouvrir le sélecteur /model puis chercher dans la liste. Maintenant, vous pouvez saisir directement /model nom-du-modèle.
Ce que vous pouvez faire avec :
- Passer le sélecteur : par exemple
/model qwen3.6-plus - Comparer rapidement plusieurs modèles : poser la question avec
/model A, puis recommencer avec/model B - Utiliser directement des modèles upstream une fois la base URL configurée
Voir PR #3783
📊 Améliorations
- OpenRouter passe à l’autorisation dans le navigateur : plus besoin de copier une clé API ni de maintenir une liste de modèles à la main.
/authouvre le navigateur, sauvegarde la clé et récupère le catalogue de modèles ;/manage-modelsajoute recherche, filtres et activation (#3576 ) - La Todo list reste visible : la dernière liste de tâches reste au-dessus de la zone de saisie et se met à jour avec les statuts, sans avoir à remonter l’historique pour retrouver la progression (#3507 , #3647 )
- Lectures de fichiers plus rapides et moins répétées : FileReadCache évite de relire le même contenu, ce qui rend les conversations multi-tours et les appels d’outils plus stables (#3717 )
- Recherche web via MCP : le provider
web_searchintégré passe à une approche MCP, compatible avec Bailian, Tavily ou GLM WebSearch Prime (#3502 ) - Première requête modèle plus rapide : préconnexion à l’endpoint API par défaut au démarrage (#3318 )
- Appels d’outils parallèles plus lisibles : les lots d’outils reçoivent des libellés sémantiques courts, pas seulement un compteur d’outils, pour comprendre plus vite ce que l’IA est en train de faire (#3538 )
- Chemin critique des outils plus rapide : moins d’I/O synchrones dans le runtime rend les longues tâches et les chaînes d’outils plus stables (#3581 )
- Titres de session régénérables :
/rename --autopeut refaire un titre automatique imprécis (#3540 ) - Les subagents au premier plan arrivent dans le panneau des tâches (#3768 )
- Chargement plus rapide des skills et activation conditionnelle par chemin (#3604 )
- État des serveurs MCP dans la barre de statut : vous voyez rapidement si un MCP server est en ligne, ce qui facilite le diagnostic en cas de connexion instable (#3741 )
- Durée d’exécution shell plus claire : temps écoulé et timeout sont visibles (#3512 )
- Les longues commandes peuvent être proposées en arrière-plan (#3809 )
- VS Code prend en charge
/skillset/export(#2548 , #2592 ) - Configuration MCP via flags CLI : les scénarios SDK et scripts peuvent passer la configuration MCP server directement, sans modifier un fichier de configuration à la main (#1279 )
- Détection MCP plus intelligente : les requêtes de découverte MCP en double sont fusionnées afin de réduire le coût réseau au démarrage (#3818 )
- Les slash commands affichent des indices de paramètres (#3593 )
- Interface en chinois traditionnel via
/language ui zh-TW(#3569 ) - Copie plus simple dans le Webview VS Code avec le clic droit natif (#3477 )
- Appels d’outils MCP plus complets en mode ACP avec serveurs SSE/HTTP et appels concurrents (#3574 , #3463 )
🔧 Correctifs importants
| PR | Version | Correctif | Impact |
|---|---|---|---|
| #3645 | v0.15.6 | Priorité de sélection modèle corrigée : argv > settings > auth env vars | Un modèle passé en CLI remplace correctement la configuration |
| #3820 | v0.15.7 | Lecture/écriture de chemins avec caractères spéciaux corrigée | Les chemins avec espaces ou caractères spéciaux ne bloquent plus |
| #3525 | v0.15.1 | État partagé du parser de tool calls streaming corrigé | Les sorties multi-tours ne se mélangent plus |
| #3533 | v0.15.1 | Boucle de rendu de slash completion corrigée | Les commandes slash ne figent plus l’interface |
| #3753 | v0.15.7 | Proxy non appliqué corrigé | Les environnements entreprise/intranet fonctionnent mieux |
| #3656 | v0.15.4 | Récupération des enregistrements session JSONL collés améliorée | Les journaux de session anormaux sont plus faciles à récupérer sans perdre le contexte |
| #3547 | v0.15.3 | Rerenders inutiles de l’historique corrigés | L’historique est plus fluide |
| #3600 | v0.15.4 | Parsing des commandes shell multilignes corrigé | Les commandes multilignes sont moins souvent découpées à tort |
| #3531 | v0.15.2 | Ordre des prompts historiques renvoyés corrigé | Les prompts renvoyés reviennent à la bonne position, ce qui garde le contexte suivant cohérent |
| #3544 | v0.15.2 | Résidus du protocole clavier Kitty après SIGINT corrigés | Plus de caractères parasites après interruption |
| #3617 | v0.15.4 | Format des résultats multimédia en mode OpenAI strict corrigé | Les providers compatibles OpenAI sont plus stables |
| #3691 | v0.15.4 | Description de fragments reasoning avec subject corrigée | Le contenu reasoning est plus complet |
| #3559 | v0.15.2 | pages vide dans ReadFile géré correctement | Les lectures de fichiers ne sont plus rejetées par erreur |
| #3677 | v0.15.7 | Parsing des tags de pensée MiniMax corrigé | La pensée MiniMax s’affiche correctement |
| #3615 | v0.15.6 | Docs LSP, limites de chemin et taux d’appels d’outils corrigés | Les outils d’intelligence de code sont plus fiables |
| #3618 | v0.15.6 | Entrée slash command dans VS Code ne soumet plus directement | Vous pouvez compléter les paramètres avant l’envoi |
| #3752 | v0.15.6 | Persistance des dossiers ajoutés corrigée | Les répertoires de travail restent disponibles |
🎈 Autres changements
- Les tâches Auto-memory dream peuvent être annulées manuellement ; le nettoyage de mémoire en arrière-plan n’est plus impossible à interrompre (#3836 )
- Le rollback auto-memory ne bloque plus la requête principale, ce qui rend la conversation plus fluide pendant le travail en arrière-plan (#3814 )
- Les erreurs API du mode non interactif ne sont plus imprimées deux fois, pour une sortie d’erreur plus propre (#3749 )
- VS Code corrige la completion de slash command après soumission d’un message (#3609 )
qwen authajoute une option API Key (#3624 )- Chemin de dispatch de la queue slash command corrigé (#3523 )
- Clés i18n chinois/anglais réalignées (#3534 )
- Gestion des erreurs OAuth2 améliorée (#3481 )
/reviewlocal respecte maintenant/language(#3611 )- Convertisseur OpenAI rendu stateless (#3550 )
- Export Telemetry avec sérialisation JSON sûre (#3630 )
- SDK Java : variables d’environnement personnalisées au lancement du CLI (#3543 )
- SDK TypeScript v0.1.7 publié avec CLI v0.15.3 (#3688 )
.gitignoreinclut.codexpour éviter les commits de config locale (#3665 )- Suivi des tokens d’outils retiré afin de réduire le bruit dans les métriques internes (#3727 )
- Documentation de développement Qwen Code complétée pour skills, agents et AGENTS.md (#3575 )
- Workflow release : PR de merge-back stable ajoutée (#3764 )
- Auto-merge des releases SDK passé en squash merge (#3690 )
- Instructions de validation du template PR mises à jour (#3522 )
- Documentation Telemetry complétée avec l’entrée console Alibaba Cloud (#3498 )
👋 Bienvenue aux nouveaux contributeurs
- @alex-musick — changement rapide de modèle avec
/model(#3783 ) - @qiuqiuwen25 — correction des chemins avec caractères spéciaux (#3820 )
- @umut-polat — correction des erreurs API dupliquées en mode non interactif (#3749 )
- @cyphercodes — persistance des dossiers ajoutés (#3752 )
- @eliird — configuration MCP via CLI (#1279 )
- @jordimas — ajout du catalan (#3643 )
- @mohitsoni48 — format des résultats d’outils en mode OpenAI strict (#3617 )
- @Jerry2003826 — parsing des commandes shell multilignes (#3600 )
- @MikeWang0316tw — ajout du chinois traditionnel (#3569 )
- @lawrence3699 — variables d’environnement personnalisées dans le SDK Java (#3543 )
- @fyc09 — conservation du reasoning DeepSeek lors de la restauration de session (#3590 , #3737 )
Mise à jour : exécutez npm i @qwen-code/qwen-code@latest -g pour passer à la dernière version.
Pour toute question ou suggestion, ouvrez une issue sur GitHub Issues .