Qwen Code Hebdo : Channels multi-plateformes, tâches Cron planifiées, mode /plan, lancement de Qwen 3.6 Plus
Cette semaine, nous avons publié deux versions fonctionnelles v0.14.0 et v0.14.2, ainsi que deux versions de correction v0.13.2 et v0.14.1.
v0.14.0 est une mise à jour majeure :
- Le système Channels libère Qwen Code du terminal, permettant l’opération à distance via Telegram, WeChat, DingTalk et d’autres plateformes ;
- Les tâches Cron planifiées permettent à l’IA d’exécuter automatiquement des travaux répétitifs selon un calendrier ;
- Le modèle Qwen 3.6 Plus est officiellement lancé. v0.14.1 apporte des suggestions de suivi, un basculement du mode de verbosité et d’autres améliorations d’expérience.
- v0.14.2 ajoute la commande
/planen mode planification, la rétention des blocs de réflexion entre les tours, la mise à niveau des tokens de sortie adaptatifs (8K par défaut + mise à niveau automatique vers 64K), ainsi qu’un workflow de correction de bugs intégré et des compétences de débogage.
Merci aux nouveaux contributeurs de cette semaine @chinesepowered, @pic4xiu, @YingchaoX, @euxaristia, @kulikrch, @nsalvacao, @mj4444ru, @chiga0 🎉
✨ Nouvelles fonctionnalités
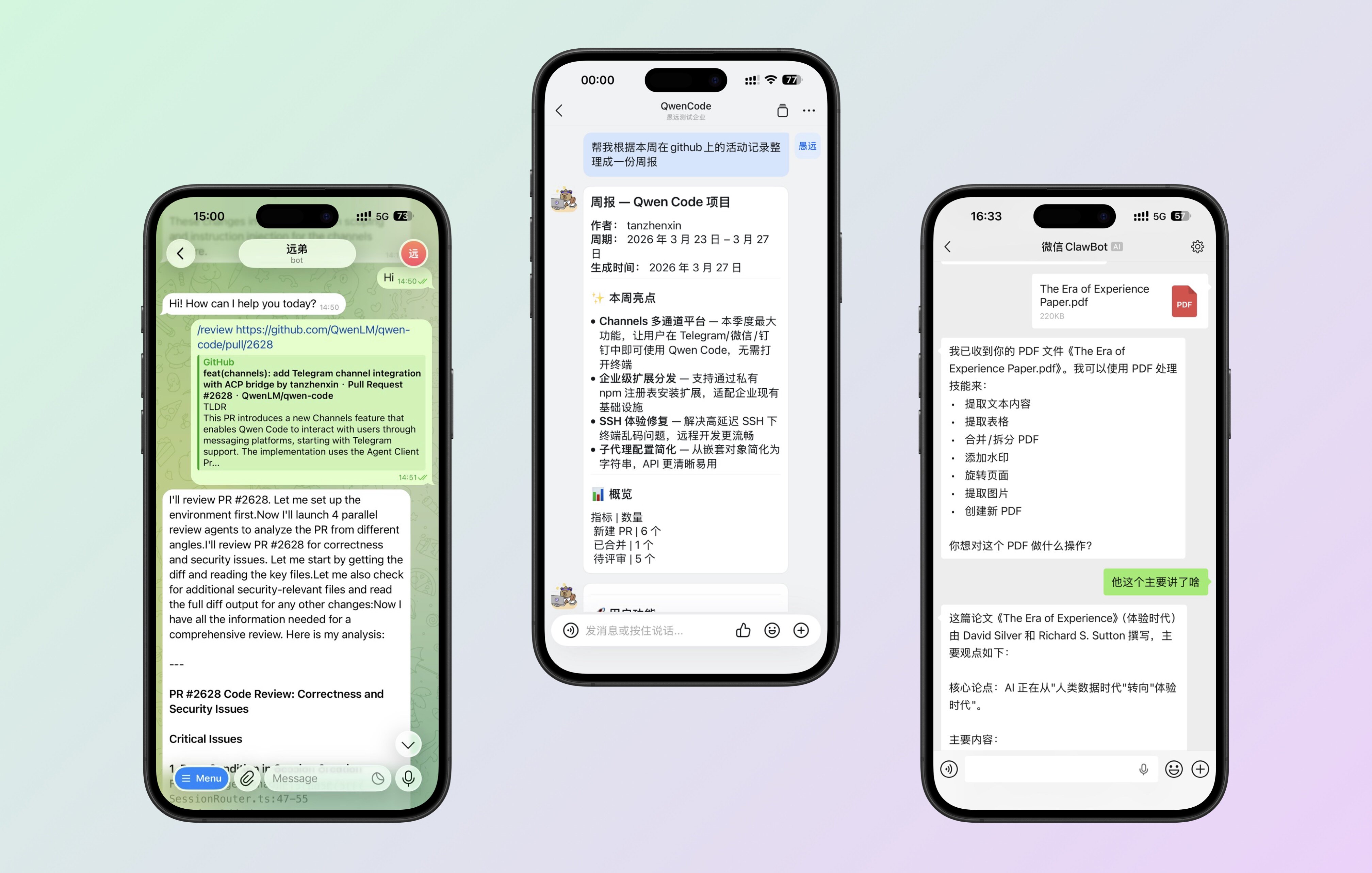
Channels : Opérez Qwen Code à distance via DingTalk, Telegram, WeChat
Qwen Code n’est plus limité au terminal. Le système Channels prend en charge l’accès par plugins à plusieurs plateformes — actuellement Telegram, WeChat et DingTalk. Vous pouvez envoyer un message au Bot depuis votre téléphone et lui faire exécuter des tâches sur votre serveur.
Ce que vous pouvez faire :
- En déplacement, envoyez un message à Qwen Code via Telegram pour exécuter un script ou consulter des logs
- Mentionnez @le bot dans un groupe DingTalk pour gérer les tâches liées au code pour l’équipe
- Envoyez un message rapide sur WeChat pour opérer votre environnement de développement à distance
Voir PR #2628
Tâches Cron planifiées : Laissez l’IA travailler selon un calendrier
Un nouvel outil Cron vous permet de configurer des tâches récurrentes planifiées dans la session en cours. L’IA les exécutera automatiquement selon votre calendrier défini sans que vous ayez à surveiller.
Ce que vous pouvez faire :
- Vérifier automatiquement si les tests passent toutes les 30 minutes
- Récupérer automatiquement le dernier code et lancer un build chaque matin
- Surveiller les fichiers de logs selon un calendrier et vous notifier en cas d’anomalies
Voir PR #2731
Comment activer ?
Ajoutez dans ~/.qwen/settings.json :
{
"experimental":{
"cron": true
}
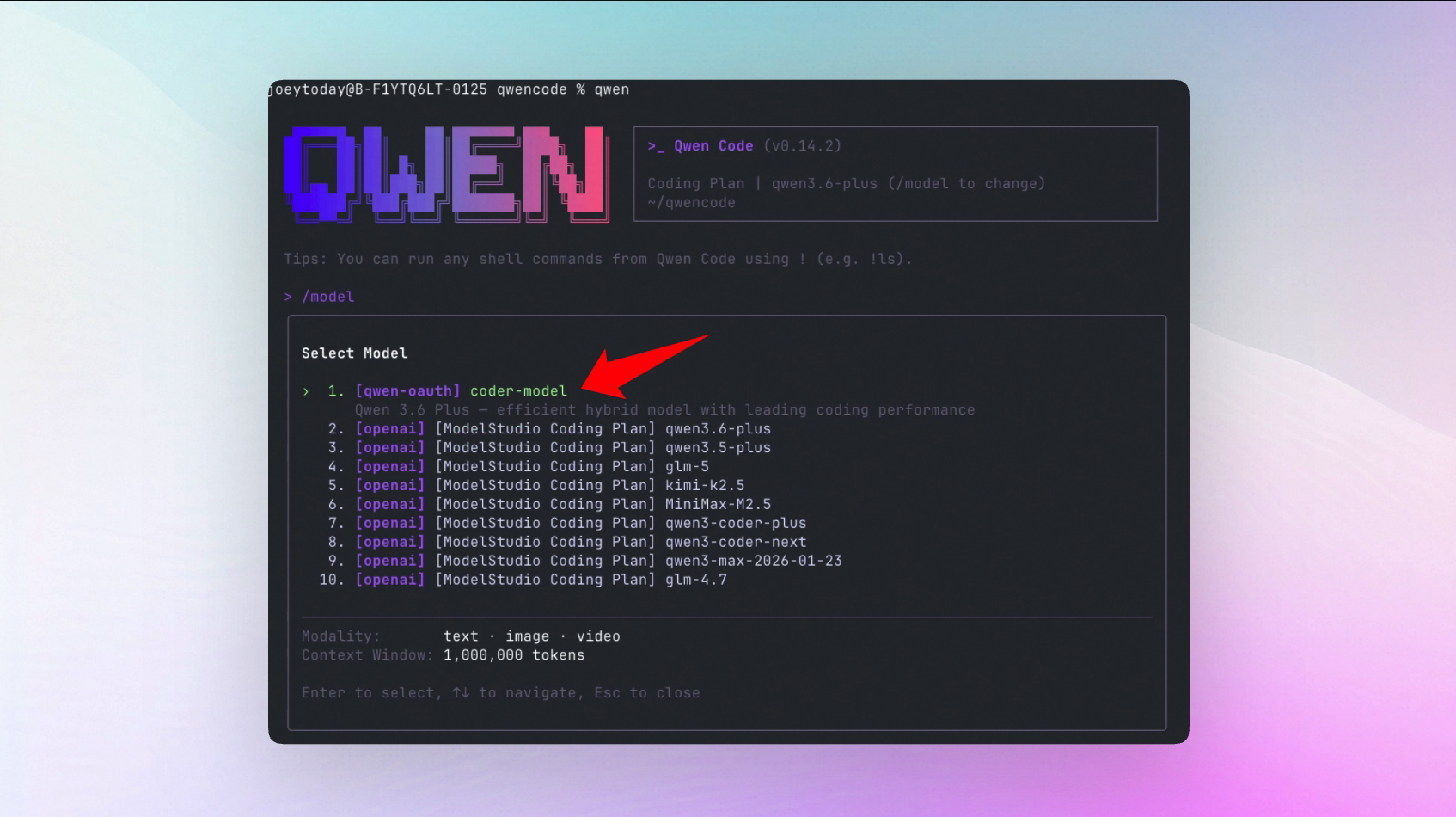
}Lancement du modèle Qwen 3.6 Plus
Qwen 3.6 Plus est officiellement disponible dans Qwen Code, gratuit. Ses performances en programmation sont comparables à GPT-5 et Claude 3.7 Sonnet, avec des avantages notables en compréhension du chinois et traitement de longs contextes. Le plan Coding d’Alibaba Cloud ModelStudio est également disponible.
Ce que vous pouvez faire :
- Utiliser directement le dernier modèle Qwen 3.6 Plus dans Qwen Code
- 1 000 appels gratuits/jour, contexte de 1 million de tokens
- Meilleure expérience pour les scénarios de programmation en chinois
Voir PR #2820
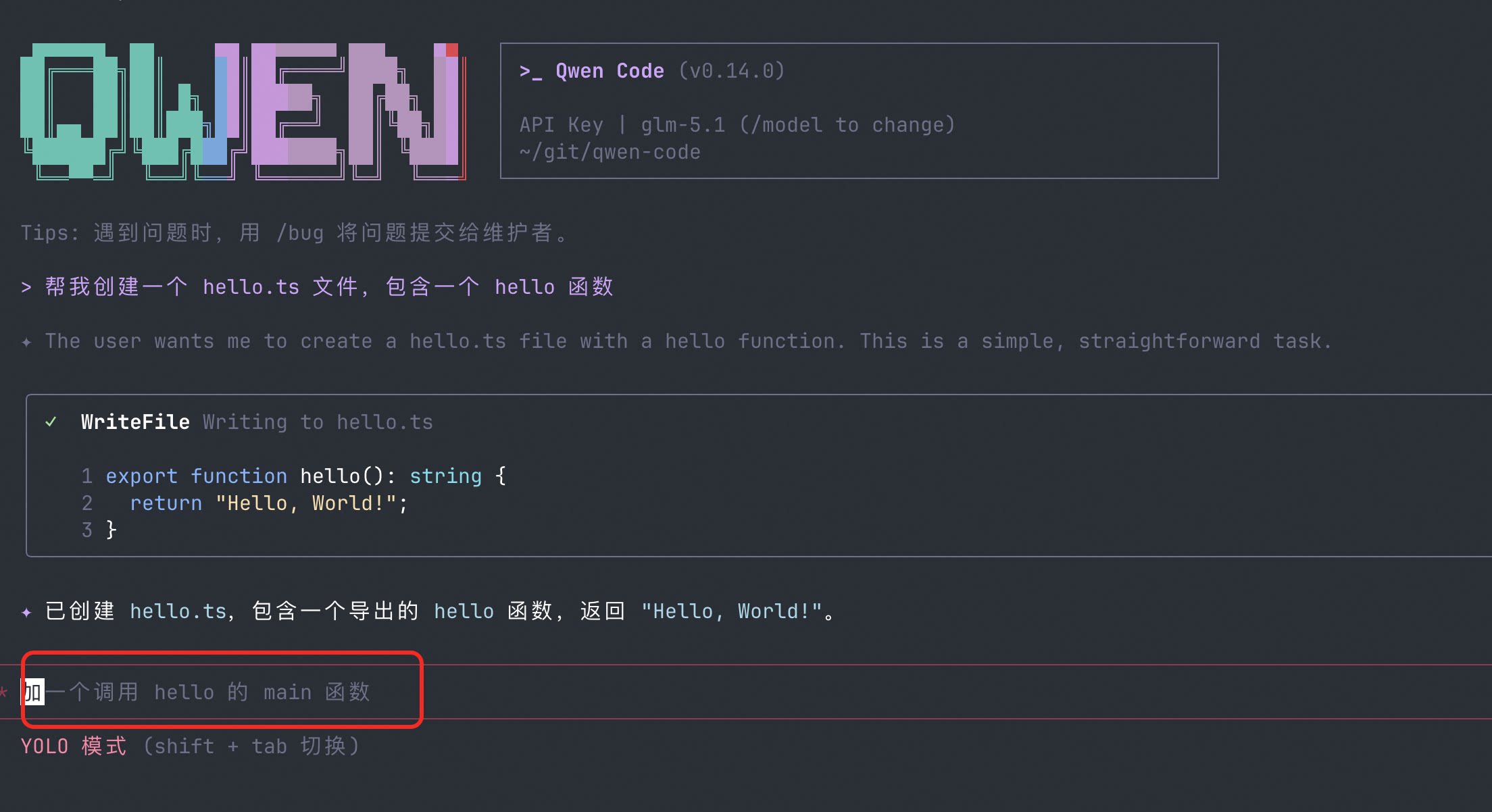
Suggestions de suivi : L’IA vous dit quoi faire ensuite
Après avoir terminé une tâche, l’IA fournit automatiquement 2-3 suggestions de suivi. Pas besoin de réfléchir à « que faire ensuite » — cliquez simplement pour continuer.
Ce que vous pouvez faire :
- Après avoir écrit un composant, l’IA suggère « Voulez-vous ajouter des tests unitaires ? » — cliquez pour commencer
- Après avoir corrigé un bug, l’IA suggère « Voulez-vous vérifier des endroits similaires ? » — vous évite de réfléchir
- Quand les débutants ne savent pas quoi faire ensuite, les suggestions de suivi servent de guide
Voir PR #2525
Comment activer ?
Ajoutez dans ~/.qwen/settings.json :
{
"ui":{
"enableFollowupSuggestions": true
}
}Pour des temps de réponse plus rapides, vous pouvez utiliser /model --fast pour spécifier un modèle léger dédié aux suggestions en arrière-plan.
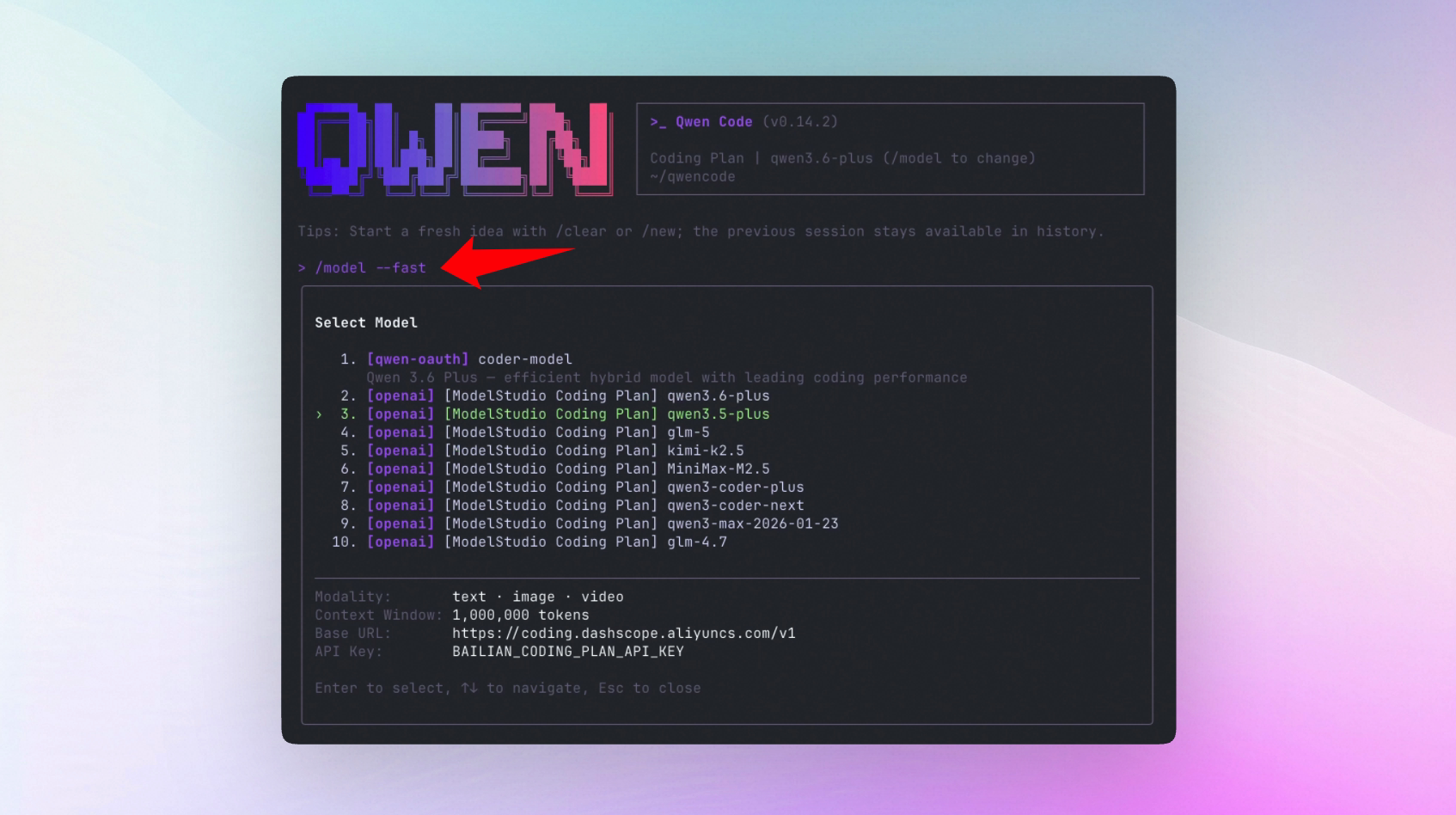
Sélection de modèle croisé pour les sous-agents : Différents modèles pour différentes tâches
Les sous-agents peuvent désormais utiliser des modèles différents de l’agent principal. Utilisez un modèle puissant pour la tâche principale pour garantir la qualité, et un modèle léger pour les sous-tâches pour accélérer — des combinaisons flexibles qui économisent des tokens sans sacrifier la qualité.
Ce que vous pouvez faire :
- Utiliser Qwen 3.6 Plus pour la tâche principale et un modèle léger pour les sous-tâches, réduisant la consommation de tokens tout en maintenant la qualité pour les tâches critiques
- Différents types de sous-tâches se voient automatiquement attribuer le modèle le plus adapté
Voir PR #2698
Comment commencer ?
Créez un fichier Skill de sous-agent spécifiant un modèle différent :
---
name: test-cross-provider
description: Test d'Agent cross-provider
model: openai:gpt-4o
---
Vous êtes un assistant de test. Veuillez vous présenter brièvement, en incluant le nom du modèle que vous utilisez.Ensuite, dites à Qwen Code d’invoquer ce sous-agent dans la conversation.
Basculement de verbosité Ctrl+O : Changez le niveau de détail en une touche
Appuyez sur Ctrl+O pour basculer entre les modes verbose (détaillé) et compact (concis). Affichez la sortie détaillée lors du débogage, passez en mode compact pour l’utilisation quotidienne — aucune modification de configuration nécessaire.
Ce que vous pouvez faire :
- Passer en mode verbose lors du débogage pour voir le processus d’exécution complet
- Passer en mode compact pour l’utilisation quotidienne pour une interface plus épurée
- Basculer à tout moment sans redémarrer ni modifier les fichiers de configuration
Voir PR #2770
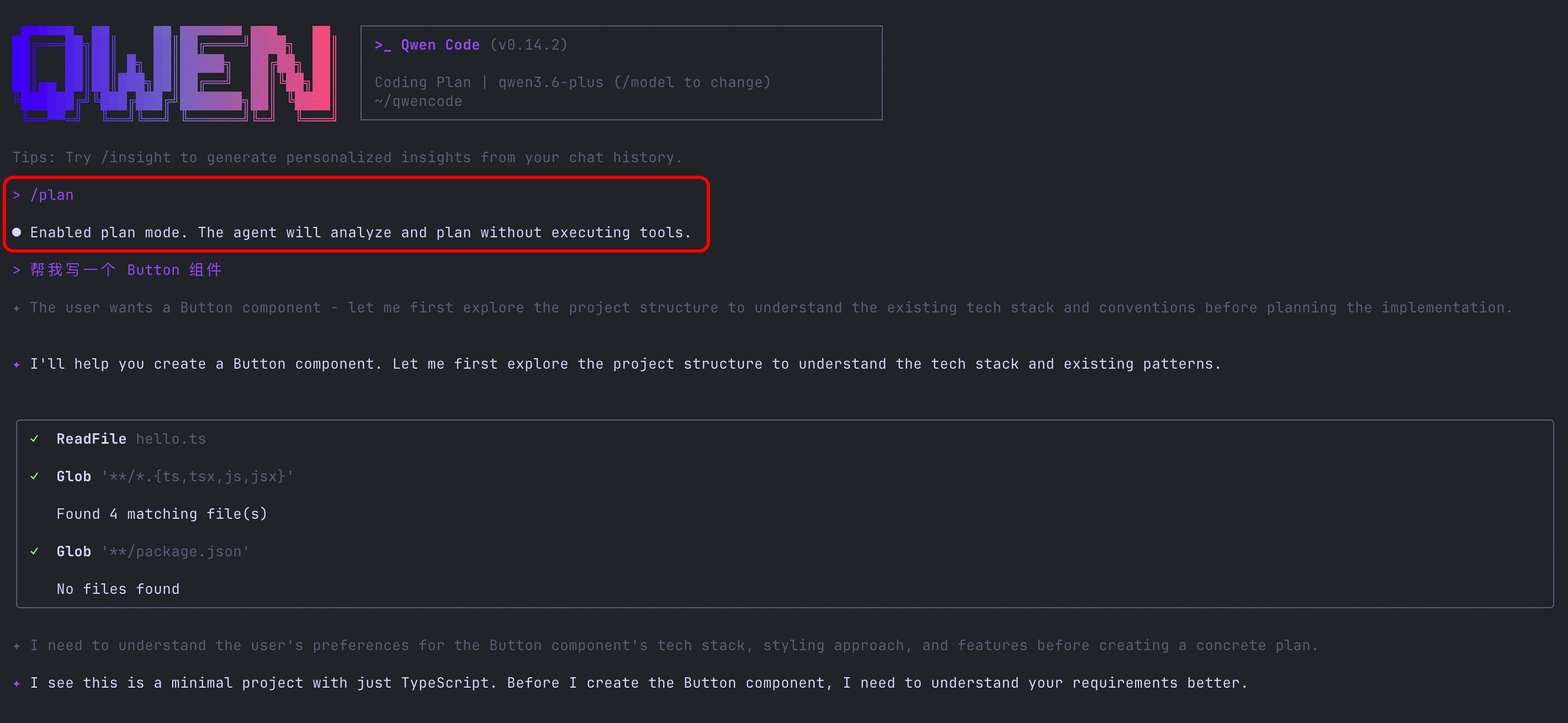
Commande /plan : Planifiez avant d’agir
La nouvelle commande /plan vous permet d’entrer en mode planification en une commande. L’IA fournira d’abord un plan d’exécution complet, et vous confirmez avant qu’elle ne commence l’exécution. Parfait pour les tâches complexes — voyez d’abord la vue d’ensemble, puis avancez étape par étape.
Ce que vous pouvez faire :
- Avant de refactoriser un grand module, demandez à l’IA de lister tous les fichiers et étapes à modifier
- Examinez d’abord le plan pour les tâches multi-étapes afin d’éviter que l’IA ne dévie et qu’il faille tout recommencer
- En collaboration d’équipe, générez un plan à faire confirmer par les collègues avant l’exécution
Voir PR #2921
Tokens de sortie adaptatifs : Les réponses ne sont plus tronquées
Les tokens de sortie sont par défaut à 8K. Quand l’IA détecte qu’une réponse est tronquée, elle passe automatiquement à 64K et réessaie. Pas besoin d’ajuster manuellement les paramètres — l’IA détermine elle-même l’espace de réponse nécessaire.
Ce que vous pouvez faire :
- La génération de longs fichiers n’est plus tronquée — contenu complet en une seule sortie
- Génération de code complexe sans avoir à assembler des segments
- Pas besoin de configurer manuellement max_tokens — l’IA s’adapte automatiquement
Voir PR #2898
Rétention des blocs de réflexion entre les tours
Le processus de réflexion de l’IA (thinking block) peut désormais être conservé entre les tours de conversation, avec un nettoyage automatique pendant les temps d’inactivité. Dans les conversations multi-tours, l’IA peut mieux poursuivre sa chaîne de raisonnement précédente pour des réponses plus cohérentes.
Voir PR #2897
📊 Améliorations
| PR | Version | Amélioration | Impact |
|---|---|---|---|
| #2781 | v0.14.0 | Hooks en version stable : suppression du drapeau expérimental, ajout de l’UI d’état désactivé | Possibilité de désactiver temporairement un Hook sans supprimer la config, plus stable en tant que fonctionnalité officielle |
| #2687 | v0.14.0 | /review amélioré : ajout d’étapes de validation et contrôle des faux positifs, support des commentaires sur les PR | Résultats de review plus précis, moins d’avertissements inutiles |
| #2776 | v0.14.1 | /btw question latérale améliorée : qualité des prompts améliorée, ajout de Ctrl+C/D pour annuler | Expérience de question latérale plus fluide, appuyez sur Ctrl+C à tout moment pour annuler |
| #2719 | v0.14.0 | Les extensions supportent l’installation npm | En plus des URL GitHub, vous pouvez maintenant installer des extensions depuis le registre npm |
| #2428 | v0.14.0 | Reconnexion automatique MCP, ajout de la commande /mcp reconnect | MCP se rétablit automatiquement après déconnexion, pas besoin de redémarrer à chaque fois |
| #2889 | v0.14.1 | Guide des opérations dangereuses : le prompt système ajoute un guide de comportement pour les opérations dangereuses | L’IA confirmera plus soigneusement avant d’exécuter des suppressions, écrasements et autres opérations, réduisant les opérations accidentelles |
| #2659 | v0.14.0 | Optimisation de /compress : gestion correcte des conversations intensives en appels d’outils | La compression des longues conversations ne perd plus le contexte clé |
| #2595 | v0.14.1 | Standardisation des étiquettes d’outils WebUI | Les noms d’outils s’affichent de manière plus cohérente et claire dans l’interface WebUI |
| #2954 | v0.14.2 | Suggestions de suivi désactivées par défaut | Plus d’interruption par des suggestions automatiques, activez dans les paramètres si nécessaire |
🔧 Corrections importantes
| PR | Version | Correction | Impact |
|---|---|---|---|
| #2733 | v0.13.2 | Correction de la résolution de chemin node-pty sur Windows Git Bash | Les utilisateurs Windows Git Bash ne rencontrent plus d’erreurs au démarrage |
| #2656 | v0.13.2 | Correction du lag de /clear et de la touche ESC causé par le système Hooks | Les opérations d’effacement d’écran et d’annulation sont à nouveau fluides |
| #2707 | v0.13.2 | Préservation des fins de ligne originales (CRLF/LF) lors de l’édition de fichiers | Plus de modification des fins de ligne lors de la collaboration multiplateforme |
| #2718 | v0.13.2 | Correction de la fuite de réponse terminal dans les environnements SSH à haute latence | La sortie ne se sérialise plus lors du développement distant SSH |
| #2777 | v0.14.0 | Mise à niveau de node-pty pour corriger la fuite de descripteurs de fichiers PTY sur macOS | Plus de ralentissement dû aux fuites FD lors d’une utilisation prolongée |
| #2662 | v0.14.0 | Nettoyage des processus orphelins à la fermeture des onglets, nettoyage des sous-processus MCP à la sortie | Plus de processus en arrière-plan persistants consommant des ressources après la sortie |
| #2884 | v0.14.1 | Restauration du raccourci ? en mode normal vim | Le raccourci de recherche des utilisateurs vim fonctionne à nouveau normalement |
| #2837 | v0.14.1 | Suppression de la détection de glissement de guillemets, correction du délai de saisie | Plus de délai de saisie notable lors de la frappe |
| #2834 | v0.14.1 | /theme restaure le thème précédent lors de l’annulation | L’annulation du changement de thème ne reste plus bloquée dans un état intermédiaire |
| #2822 | v0.14.1 | Empêcher l’échec d’ideCommand d’affecter toutes les commandes slash | Une erreur de commande unique ne rend plus toutes les commandes indisponibles |
| #2804 | v0.14.1 | La connexion ACP ajoute la tentative de reconnexion et la reconnexion automatique | L’intégration VS Code est plus stable, récupération automatique après déconnexion |
| #2802 | v0.14.1 | Le nouvel onglet VS Code hérite de la sélection du modèle | Les nouveaux onglets ne nécessitent plus de re-sélectionner le modèle |
| #2959 | v0.14.2 | Correction de l’écran blanc webview VS Code 0.14.1 | Le panneau VS Code n’affiche plus d’écran blanc après la mise à niveau vers v0.14.1 |
| #2995 | v0.14.2 | Correction de l’erreur csiUPrefix sur Linux/Wayland | Les utilisateurs Linux Wayland ne rencontrent plus d’erreurs de saisie |
| #2976 | v0.14.2 | Les Hooks préservent le code de sortie null lors de la terminaison par signal | Les Hooks ne signalent plus incorrectement le code de sortie comme 0 lors de la terminaison par signal |
| #2858 | v0.14.1 | Correction de compatibilité des paramètres d’outils MCP (schéma anyOf/oneOf) | Plus de paramètres d’outils MCP peuvent être correctement analysés, réduisant les erreurs d’appel |
| #2943 | v0.14.1 | En-tête iLink-App-Id manquant pour le Channel WeChat | La connexion du Channel WeChat est plus stable, ne échoue plus en raison d’un en-tête manquant |
🎈 Autres améliorations
| PR | Amélioration | Impact |
|---|---|---|
| #2623 | Skill qc-helper intégré et docs de référence qwen-code-claw | Les nouveaux utilisateurs obtiennent automatiquement un guide de compétences intégré au démarrage, prise en main plus rapide |
| #2715 | Optimisation de la documentation envKey : instructions d’utilisation et exemples de champs env plus clairs | Plus besoin de deviner les formats de paramètres lors de la configuration des variables d’environnement |
| #2714 | Unification Bailian → ModelStudio | Noms de marque unifiés dans la documentation, les nouveaux utilisateurs ne seront plus confus par les anciens noms |
| #2696 | Optimisation de l’UI des événements Hooks : passage à des entrées d’historique dédiées | L’historique des conversations montre clairement quelles opérations ont été déclenchées par les Hooks |
| #2463 | Correction du rendu des tableaux Markdown | Les tableaux générés par l’IA n’ont plus de problèmes de formatage |
| #2455 | Persistance de la configuration du modèle | Les configurations de modèle personnalisées ne sont plus perdues après le redémarrage |
| #2763 | Le mode Plan supporte l’approbation de web fetch | L’IA peut maintenant naviguer sur le web pendant la phase de planification |
| #2586 | Correction de la sortie du mode YOLO | Plus de blocage en mode planification |
| sdk-typescript-v0.1.6 | SDK TypeScript v0.1.6 | API plus complète pour les développeurs intégrant les capacités de Qwen Code |
👋 Bienvenue aux nouveaux contributeurs
- @chinesepowered — Correction du nettoyage de l’écouteur d’abandon des Hooks, du rafraîchissement du cache des sous-agents, du repli des messages Telegram, et plus
- @pic4xiu — Correction du timing de commit des messages système Hook, suppression des paramètres de proxy dupliqués de WebFetchTool
- @YingchaoX — Restauration du raccourci ? en mode normal vim
- @euxaristia — Suppression de la détection de glissement de guillemets pour corriger le délai de saisie
- @kulikrch — /theme restaure le thème précédent lors de l’annulation
- @nsalvacao — Correction de exit_plan_mode en mode YOLO
- @mj4444ru — Correction de l’échappement des séparateurs de cellules de tableau Markdown
- @chiga0 — Implémentation du basculement de mode de verbosité Ctrl+O
Comment mettre à jour : Exécutez npm install -g @qwen-code/qwen-code@latest pour mettre à jour vers la dernière version.
Si vous avez des questions ou des suggestions, n’hésitez pas à nous faire part de vos retours sur GitHub Issues !