Qwen Code Wochenrückblick: Channels Multiplattform-Zugang, Cron-Aufgabenplanung, /plan Planungsmodus, Qwen 3.6 Plus Launch
Diese Woche haben wir zwei Feature-Versionen v0.14.0 und v0.14.2 sowie zwei Bugfix-Versionen v0.13.2 und v0.14.1 veröffentlicht.
v0.14.0 ist ein großes Update:
- Das Channels-System befreit Qwen Code vom Terminal und ermöglicht die Fernsteuerung über Telegram, WeChat, DingTalk und andere Plattformen;
- Cron-Aufgabenplanung lässt die KI automatisch wiederkehrende Arbeiten nach Zeitplan ausführen;
- Das Qwen 3.6 Plus Modell ist offiziell verfügbar. v0.14.1 bringt Folgevorschläge, Umschaltung des Detailmodus und weitere Erfahrungsverbesserungen.
- v0.14.2 fügt den
/planPlanungsmodus-Befehl hinzu, Thinking-Block-Beibehaltung über Gesprächsrunden, adaptives Ausgabe-Token-Upgrade (Standard 8K + automatisches Upgrade auf 64K) sowie integrierten Bugfix-Workflow und Debugging-Fähigkeiten.
Vielen Dank an die neuen Mitwirkenden dieser Woche @chinesepowered, @pic4xiu, @YingchaoX, @euxaristia, @kulikrch, @nsalvacao, @mj4444ru, @chiga0 🎉
✨ Neue Funktionen
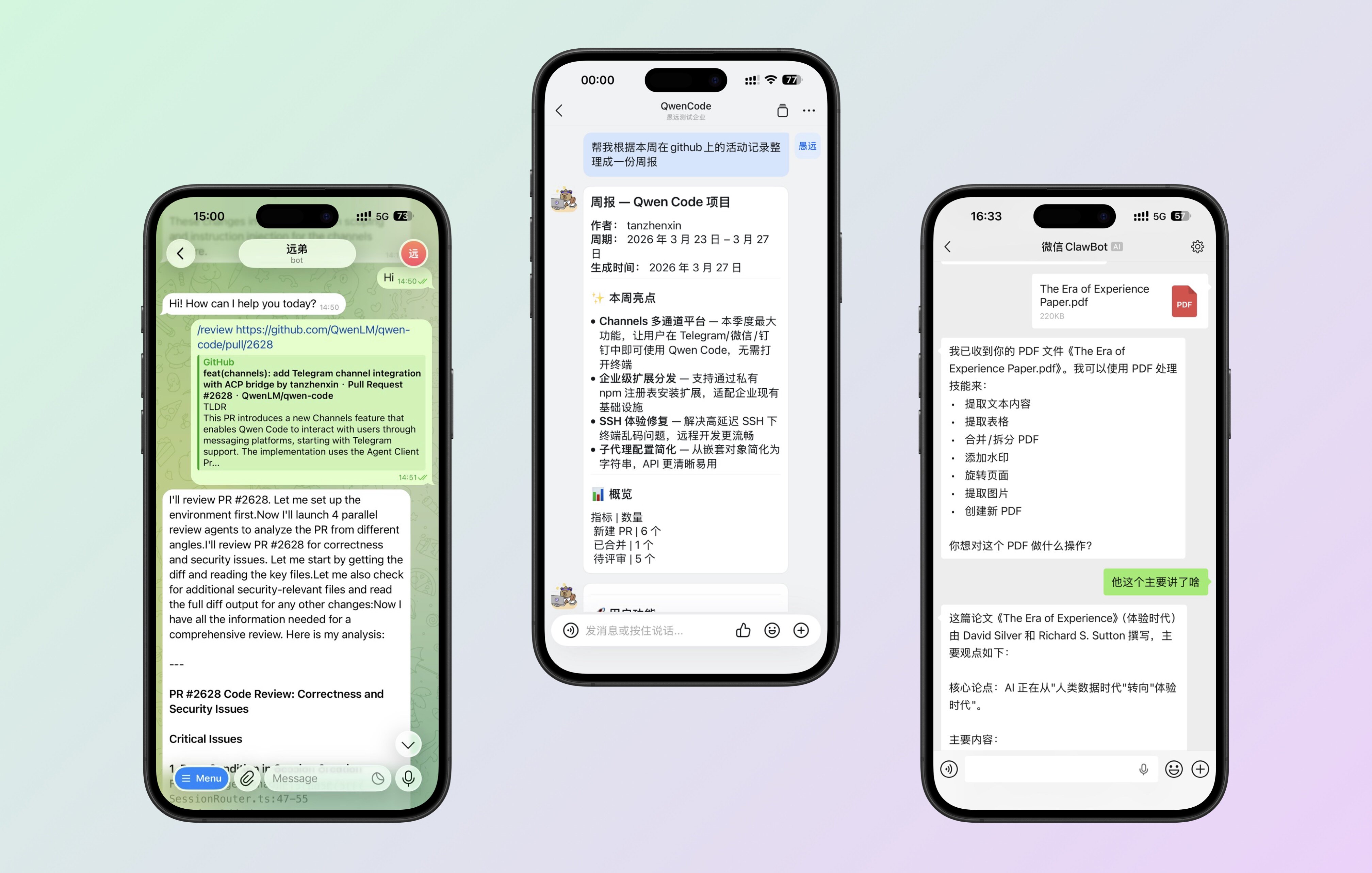
Channels: Qwen Code fernsteuern über DingTalk, Telegram, WeChat
Qwen Code ist nicht mehr auf das Terminal beschränkt. Das Channels-System unterstützt den Plugin-basierten Zugang zu mehreren Plattformen — derzeit werden Telegram, WeChat und DingTalk unterstützt. Sie können dem Bot eine Nachricht vom Handy senden und ihn Aufgaben auf Ihrem Server ausführen lassen.
Was Sie damit tun können:
- Unterwegs eine Nachricht an Qwen Code über Telegram senden, um ein Skript auszuführen oder Logs zu prüfen
- Den Bot in einer DingTalk-Gruppe @erwähnen, um codebezogene Aufgaben für das Team zu erledigen
- Eine schnelle Nachricht über WeChat senden, um Ihre Entwicklungsumgebung fernzusteuern
Siehe PR #2628
Cron-Aufgabenplanung: Lassen Sie die KI nach Zeitplan automatisch arbeiten
Ein neues Cron-Tool ermöglicht es Ihnen, geplante wiederkehrende Aufgaben innerhalb der aktuellen Sitzung einzurichten. Die KI führt sie automatisch nach Ihrem definierten Zeitplan aus, ohne dass Sie zuschauen müssen.
Was Sie damit tun können:
- Alle 30 Minuten automatisch prüfen, ob Tests bestanden werden
- Jeden Morgen automatisch den neuesten Code abrufen und einen Build ausführen
- Log-Dateien nach Zeitplan überwachen und Sie benachrichtigen, wenn Anomalien erkannt werden
Siehe PR #2731
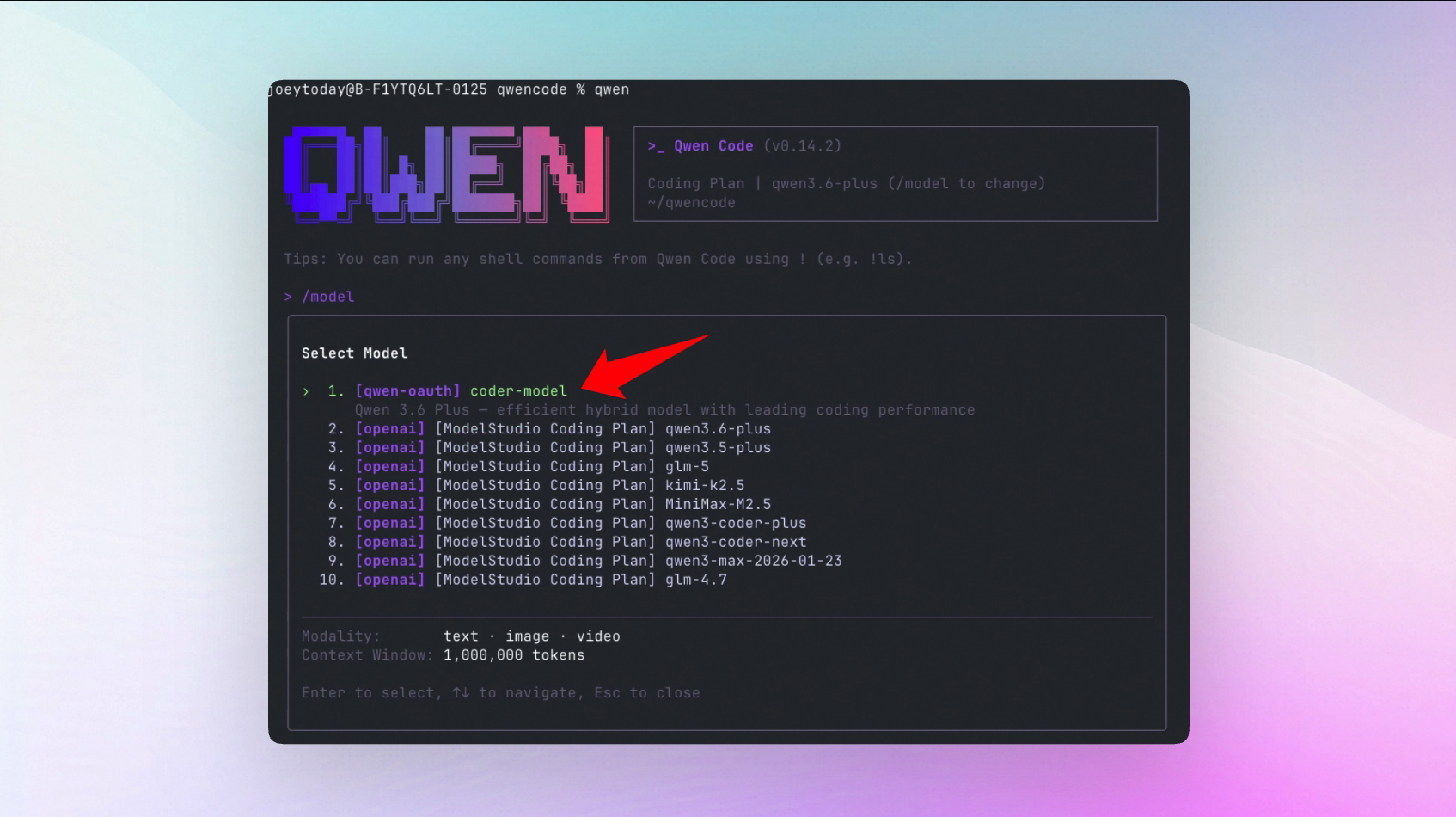
Wie aktivieren?
Fügen Sie Folgendes zu ~/.qwen/settings.json hinzu:
{
"experimental":{
"cron": true
}
}Qwen 3.6 Plus Modell-Launch
Qwen 3.6 Plus ist offiziell in Qwen Code verfügbar, kostenlos nutzbar. Seine Programmierleistung ist vergleichbar mit GPT-5 und Claude 3.7 Sonnet, mit bemerkenswerten Vorteilen beim Chinesisch-Verständnis und der Verarbeitung langer Kontexte. Der Alibaba Cloud ModelStudio Coding Plan ist ebenfalls verfügbar.
Was Sie damit tun können:
- Das neueste Qwen 3.6 Plus Modell direkt in Qwen Code verwenden
- Kostenlos 1.000 Aufrufe/Tag, 1 Million Token Kontext
- Bessere Erfahrung für chinesische Programmierszenarien
Siehe PR #2820
Folgevorschläge: Die KI sagt Ihnen, was als Nächstes zu tun ist
Nach Abschluss einer Aufgabe gibt die KI automatisch 2-3 Folgevorschläge. Sie müssen nicht selbst überlegen „was soll ich als Nächstes tun” — einfach klicken und weitermachen.
Was Sie damit tun können:
- Nach dem Schreiben einer Komponente schlägt die KI vor „Möchten Sie Unit-Tests hinzufügen?” — einfach klicken, um zu starten
- Nach dem Beheben eines Bugs schlägt die KI vor „Möchten Sie ähnliche Stellen überprüfen?” — spart Ihnen das Nachdenken
- Wenn Anfänger nicht wissen, was als Nächstes zu tun ist, dienen Folgevorschläge als Navigation
Siehe PR #2525
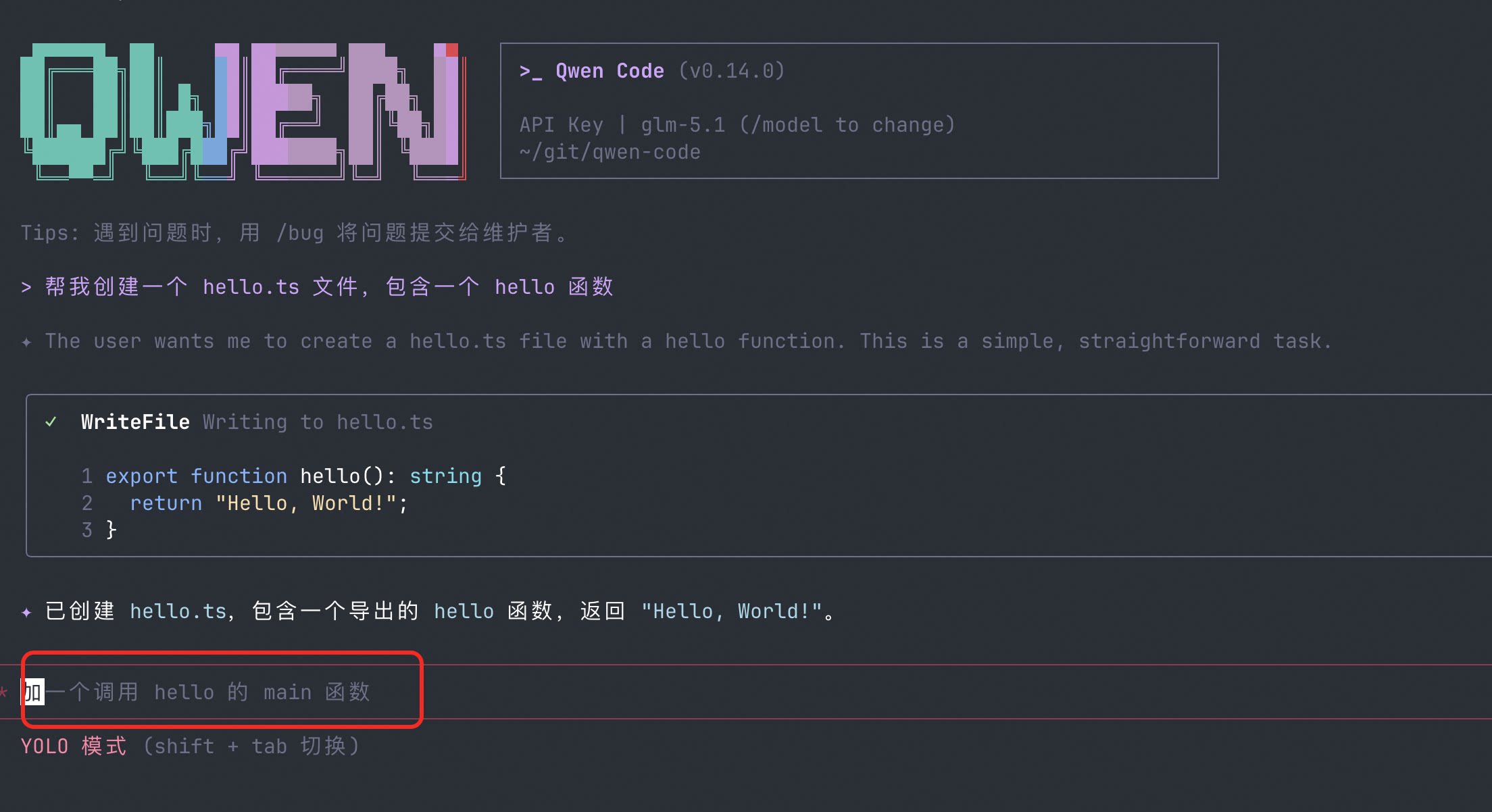
Wie aktivieren?
Fügen Sie Folgendes zu ~/.qwen/settings.json hinzu:
{
"ui":{
"enableFollowupSuggestions": true
}
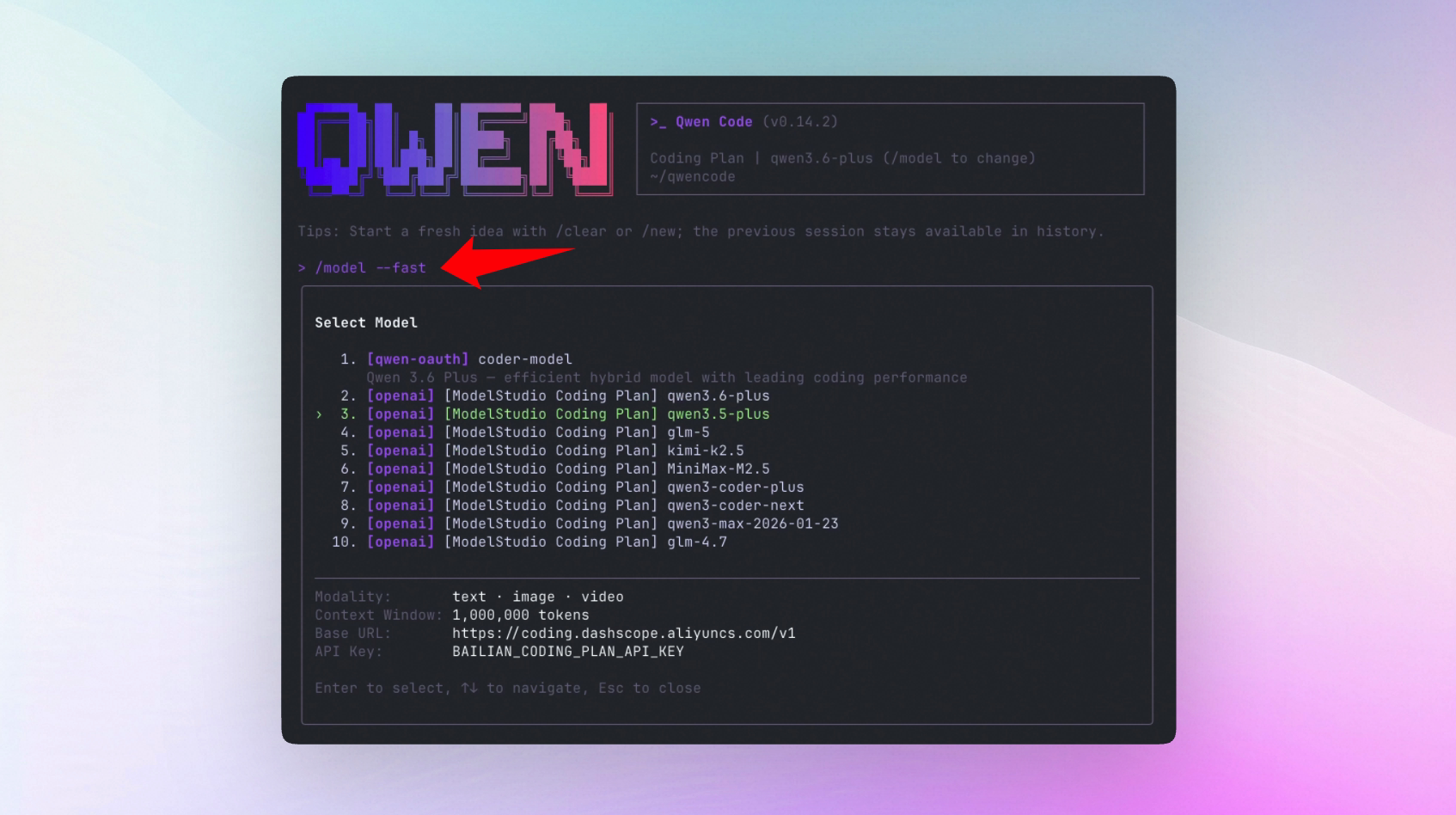
}Für schnellere Vorschlagsantwortzeiten können Sie /model --fast verwenden, um ein leichtgewichtiges Modell speziell für Hintergrundvorschläge festzulegen.
Sub-Agent Cross-Modell-Auswahl: Verschiedene Modelle für verschiedene Aufgaben
Sub-Agents können jetzt andere Modelle als der Hauptagent verwenden. Verwenden Sie ein leistungsstarkes Modell für die Hauptaufgabe zur Qualitätssicherung und ein leichtgewichtiges Modell für Unteraufgaben zur Beschleunigung — flexible Kombinationen, die Token sparen, ohne die Qualität zu beeinträchtigen.
Was Sie damit tun können:
- Qwen 3.6 Plus für die Hauptaufgabe und ein leichtgewichtiges Modell für Unteraufgaben verwenden, um den Token-Verbrauch zu reduzieren und gleichzeitig die Qualität kritischer Aufgaben beizubehalten
- Verschiedene Arten von Unteraufgaben erhalten automatisch das am besten geeignete Modell
Siehe PR #2698
Wie starten?
Erstellen Sie eine Sub-Agent Skill-Datei mit einem anderen Modell:
---
name: test-cross-provider
description: Test eines Cross-Provider-Agents
model: openai:gpt-4o
---
Sie sind ein Test-Assistent. Bitte stellen Sie sich kurz vor, einschließlich des Namens des von Ihnen verwendeten Modells.Sagen Sie dann Qwen Code in der Konversation, diesen Sub-Agent aufzurufen.
Ctrl+O Detailmodus-Umschaltung: Ausgabedetailgrad mit einer Taste ändern
Drücken Sie Ctrl+O, um zwischen verbose (detailliert) und compact (kompakt) Modus umzuschalten. Sehen Sie detaillierte Ausgaben beim Debuggen, wechseln Sie für den täglichen Gebrauch in den kompakten Modus — keine Konfigurationsänderungen nötig.
Was Sie damit tun können:
- Beim Debuggen in den verbose-Modus wechseln, um den vollständigen Ausführungsprozess zu sehen
- Für den täglichen Gebrauch in den compact-Modus wechseln für eine aufgeräumtere Oberfläche
- Jederzeit umschalten, ohne Neustart oder Bearbeitung von Konfigurationsdateien
Siehe PR #2770
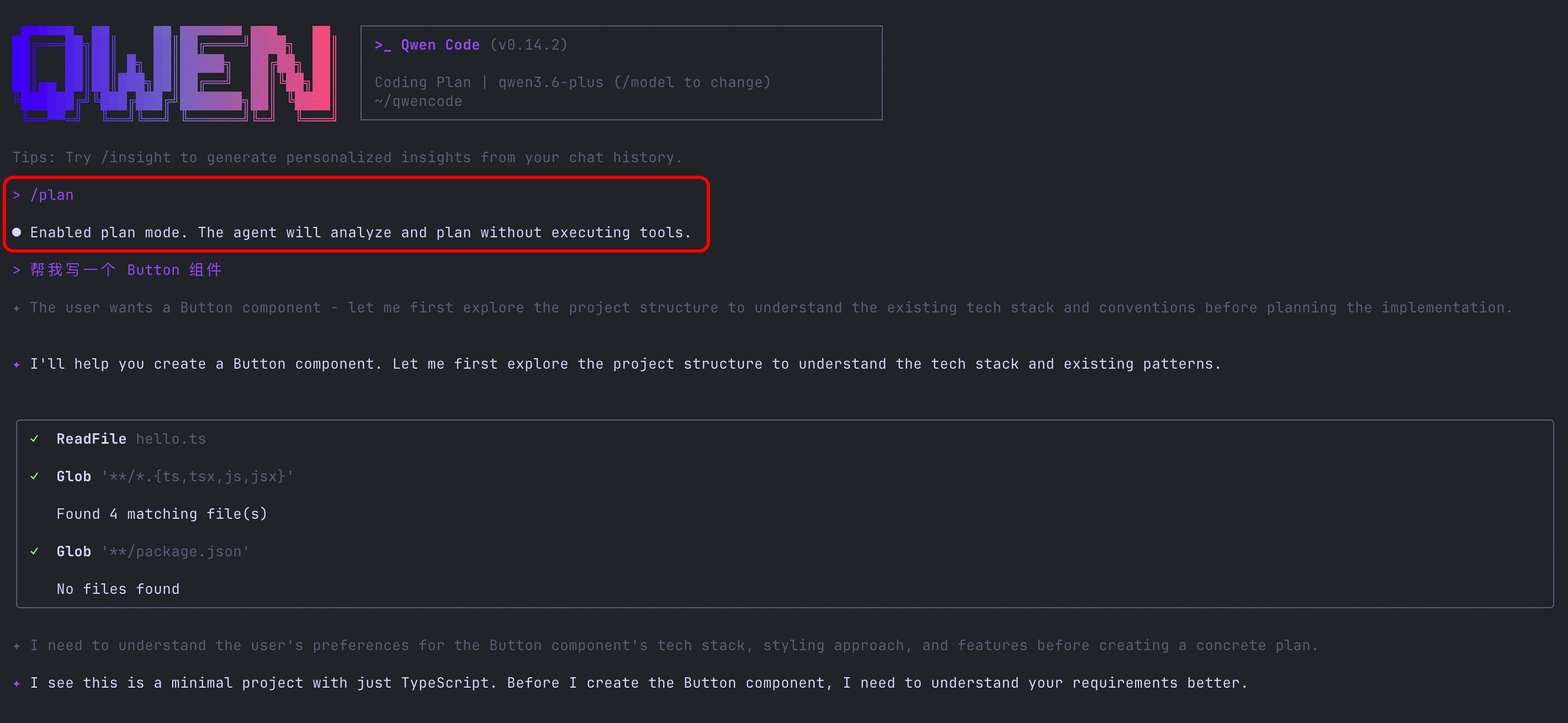
/plan Befehl: Planen vor dem Handeln
Der neue /plan Befehl ermöglicht es Ihnen, mit einem Befehl in den Planungsmodus zu wechseln. Die KI liefert zuerst einen vollständigen Ausführungsplan, und Sie bestätigen, bevor die Ausführung beginnt. Perfekt für komplexe Aufgaben — erst das Gesamtbild sehen, dann Schritt für Schritt vorgehen.
Was Sie damit tun können:
- Vor dem Refactoring eines großen Moduls die KI alle zu ändernden Dateien und Schritte auflisten lassen
- Bei mehrstufigen Aufgaben zuerst den Plan prüfen, um zu vermeiden, dass die KI vom Kurs abkommt und von vorne begonnen werden muss
- In der Teamarbeit zuerst einen Plan zur Bestätigung durch Kollegen generieren, dann ausführen
Siehe PR #2921
Adaptive Ausgabe-Token: Antworten werden nicht mehr abgeschnitten
Ausgabe-Token sind standardmäßig 8K. Wenn die KI erkennt, dass eine Antwort abgeschnitten wird, wird automatisch auf 64K aufgerüstet und erneut versucht. Sie müssen keine Parameter manuell anpassen — die KI bestimmt selbst, wie viel Antwortplatz sie benötigt.
Was Sie damit tun können:
- Lange Dateigenerierung wird nicht mehr abgeschnitten — vollständiger Inhalt in einer Ausgabe
- Komplexe Codegenerierung ohne Zusammenstückeln von Segmenten
- Kein manuelles Konfigurieren von max_tokens nötig — die KI passt sich automatisch an
Siehe PR #2898
Thinking-Block-Beibehaltung über Gesprächsrunden
Der Denkprozess der KI (Thinking Block) kann jetzt über Gesprächsrunden hinweg beibehalten werden, mit automatischer Bereinigung in Leerlaufzeiten. In mehrstufigen Gesprächen kann die KI ihre vorherige Argumentationskette besser fortsetzen und kohärentere Antworten liefern.
Siehe PR #2897
📊 Verbesserungen
| PR | Version | Verbesserung | Auswirkung |
|---|---|---|---|
| #2781 | v0.14.0 | Hooks GA: Experimentelles Flag entfernt, Deaktivierungsstatus-UI hinzugefügt | Hook kann vorübergehend deaktiviert werden, ohne die Konfiguration zu löschen, stabiler als offizielle Funktion |
| #2687 | v0.14.0 | /review verbessert: Validierungsschritte und Falsch-Positiv-Kontrolle hinzugefügt, Unterstützung für Kommentare zu PRs | Review-Ergebnisse sind genauer, weniger sinnlose Warnungen |
| #2776 | v0.14.1 | /btw Seitenfrage verbessert: Prompt-Qualität verbessert, Ctrl+C/D zum Abbrechen hinzugefügt | Seitenfrage-Erfahrung ist flüssiger, jederzeit Ctrl+C zum Abbrechen |
| #2719 | v0.14.0 | Erweiterungen unterstützen npm-Installation | Neben GitHub-URLs können Erweiterungen jetzt auch aus der npm-Registry installiert werden |
| #2428 | v0.14.0 | MCP automatische Wiederverbindung, /mcp reconnect Befehl hinzugefügt | MCP stellt sich nach Verbindungsabbruch automatisch wieder her, kein Neustart nötig |
| #2889 | v0.14.1 | Anleitung für gefährliche Operationen: System-Prompt fügt Verhaltensanleitung für gefährliche Operationen hinzu | KI bestätigt sorgfältiger vor dem Ausführen von Lösch-, Überschreib- und anderen Operationen, weniger versehentliche Operationen |
| #2659 | v0.14.0 | /compress Optimierung: korrekte Verarbeitung von Tool-Aufruf-intensiven Gesprächen | Komprimierung langer Gespräche verliert keinen wichtigen Kontext mehr |
| #2595 | v0.14.1 | WebUI Tool-Label-Standardisierung | Tool-Namen werden in der WebUI-Oberfläche einheitlicher und klarer angezeigt |
| #2954 | v0.14.2 | Folgevorschläge standardmäßig deaktiviert | Keine Unterbrechung durch automatische Vorschläge, bei Bedarf in den Einstellungen aktivieren |
🔧 Wichtige Fehlerbehebungen
| PR | Version | Fehlerbehebung | Auswirkung |
|---|---|---|---|
| #2733 | v0.13.2 | node-pty Pfadauflösung unter Windows Git Bash behoben | Windows Git Bash-Benutzer stoßen nicht mehr auf Startfehler |
| #2656 | v0.13.2 | /clear und ESC-Taste Verzögerung durch Hooks-System behoben | Bildschirm-Lösch- und Abbruchoperationen sind wieder flüssig |
| #2707 | v0.13.2 | Originale Zeilenenden (CRLF/LF) beim Bearbeiten von Dateien beibehalten | Keine Verfälschung der Zeilenenden mehr bei plattformübergreifender Zusammenarbeit |
| #2718 | v0.13.2 | Terminal-Antwort-Leck in SSH-Umgebungen mit hoher Latenz behoben | Ausgabe serialisiert nicht mehr bei SSH-Remote-Entwicklung |
| #2777 | v0.14.0 | node-pty aktualisiert zur Behebung des macOS PTY-Dateideskriptor-Lecks | Keine Verzögerungen mehr durch FD-Lecks bei längerer Nutzung |
| #2662 | v0.14.0 | Verwaiste Prozesse beim Schließen von Tabs bereinigen, MCP-Unterprozesse beim Beenden bereinigen | Keine verbleibenden Hintergrundprozesse mehr, die nach dem Beenden Ressourcen verbrauchen |
| #2884 | v0.14.1 | ?-Tastenkürzel im vim Normal-Modus wiederhergestellt | Such-Tastenkürzel für vim-Benutzer funktioniert wieder normal |
| #2837 | v0.14.1 | Anführungszeichen-Drag-Erkennung entfernt, Eingabeverzögerung behoben | Keine spürbare Eingabeverzögerung mehr beim Tippen |
| #2834 | v0.14.1 | /theme stellt vorheriges Theme beim Abbrechen wieder her | Abbrechen des Theme-Wechsels bleibt nicht mehr in einem Zwischenzustand stecken |
| #2822 | v0.14.1 | Verhindern, dass ideCommand-Fehler alle Slash-Befehle beeinträchtigen | Ein einzelner Befehlsfehler macht nicht mehr alle Befehle unverfügbar |
| #2804 | v0.14.1 | ACP-Verbindung fügt Wiederholung und automatische Wiederverbindung hinzu | VS Code-Integration ist stabiler, automatische Wiederherstellung nach Verbindungsabbruch |
| #2802 | v0.14.1 | Neuer VS Code-Tab erbt Modellauswahl | Neue Tabs erfordern keine erneute Modellauswahl mehr |
| #2959 | v0.14.2 | VS Code 0.14.1 Webview-Weißbildschirm behoben | VS Code-Panel zeigt nach dem Upgrade auf v0.14.1 keinen weißen Bildschirm mehr |
| #2995 | v0.14.2 | csiUPrefix-Fehler unter Linux/Wayland behoben | Linux Wayland-Benutzer stoßen nicht mehr auf Eingabefehler |
| #2976 | v0.14.2 | Hooks bewahren null Exit-Code bei Signal-Terminierung | Hooks melden den Exit-Code nicht mehr fälschlicherweise als 0 bei Signal-Terminierung |
| #2858 | v0.14.1 | MCP-Tool-Parameter-Kompatibilitätsfix (anyOf/oneOf Schema) | Mehr MCP-Tool-Parameter können korrekt geparst werden, weniger Aufruffehler |
| #2943 | v0.14.1 | Fehlender iLink-App-Id Header im WeChat Channel | WeChat Channel-Verbindung ist stabiler, scheitert nicht mehr wegen fehlendem Header |
🎈 Weitere Verbesserungen
| PR | Verbesserung | Auswirkung |
|---|---|---|
| #2623 | Integrierter qc-helper Skill und qwen-code-claw Referenzdokumentation | Neue Benutzer erhalten beim Start automatisch integrierte Skill-Anleitung, schnelleres Onboarding |
| #2715 | envKey-Dokumentationsoptimierung: klarere Nutzungsanweisungen und env-Feld-Beispiele | Kein Raten mehr bei Parameterformaten beim Konfigurieren von Umgebungsvariablen |
| #2714 | Bailian → ModelStudio Vereinheitlichung | Einheitliche Markennamen in der Dokumentation, neue Benutzer werden nicht durch alte Namen verwirrt |
| #2696 | Hooks-Event-UI-Optimierung: Wechsel zu dedizierten Verlaufseinträgen | Gesprächsverlauf zeigt klar, welche Operationen von Hooks ausgelöst wurden |
| #2463 | Markdown-Tabellen-Rendering-Fix | Von KI generierte Tabellen haben keine Formatierungsprobleme mehr |
| #2455 | Modellkonfiguration-Persistenz | Benutzerdefinierte Modellkonfigurationen gehen nach dem Neustart nicht mehr verloren |
| #2763 | Plan-Modus unterstützt Web-Fetch-Genehmigung | KI kann jetzt auch in der Planungsphase Webseiten durchsuchen |
| #2586 | YOLO-Modus-Exit-Fix | Bleibt nicht mehr im Planungsmodus stecken |
| sdk-typescript-v0.1.6 | SDK TypeScript v0.1.6 | Vollständigere API für Entwickler, die Qwen Code-Fähigkeiten integrieren |
👋 Willkommen neue Mitwirkende
- @chinesepowered — Hooks Abort-Listener-Bereinigung, Sub-Agent-Cache-Aktualisierung, Telegram-Nachrichten-Fallback und weitere Probleme behoben
- @pic4xiu — Hook-System-Nachrichten-Commit-Timing behoben, doppelte Proxy-Einstellungen von WebFetchTool entfernt
- @YingchaoX — ?-Tastenkürzel im vim Normal-Modus wiederhergestellt
- @euxaristia — Anführungszeichen-Drag-Erkennung entfernt zur Behebung der Eingabeverzögerung
- @kulikrch — /theme stellt vorheriges Theme beim Abbrechen wieder her
- @nsalvacao — exit_plan_mode im YOLO-Modus behoben
- @mj4444ru — Markdown-Tabellenzellen-Trennzeichen-Escaping behoben
- @chiga0 — Ctrl+O Detailmodus-Umschaltung implementiert
So aktualisieren Sie: Führen Sie npm install -g @qwen-code/qwen-code@latest aus, um auf die neueste Version zu aktualisieren.
Wenn Sie Fragen oder Vorschläge haben, geben Sie gerne Feedback auf GitHub Issues !