Qwen Code Semanal: DeepSeek V4 com contexto de um milhão, tarefas em segundo plano unificadas e conversas com rewind
Nesta semana lançamos a v0.15.7 como versão principal de funcionalidades, além de seis versões incrementais (v0.15.1-v0.15.6).
DeepSeek V4 foi um dos principais assuntos da comunidade de IA nesta semana. Enquanto o mecanismo de inferência local do antirez circulava no HN e os provedores corriam para adicionar suporte, o Qwen Code também recebeu a integração: janela de contexto de 1M, limite de saída de 384K, reasoning effort “max” e correções para thinking blocks.
Multitarefa com agents está se tornando uma direção clara em ferramentas para desenvolvedores, inclusive em OpenAI Codex e Google AlphaEvolve. No Qwen Code, isso agora aparece como um painel de tarefas de verdade: você vê tudo que está rodando em segundo plano, cancela o que não precisa mais e retoma tarefas depois de uma interrupção. O GitHub também acabou de publicar orientações para revisão de PRs por agents; na mesma linha, ampliamos o qwen review com novos subcomandos e agents para executar uma revisão completa pelo terminal.
Também reduzimos pequenas fricções do dia a dia. Se a conversa sair do rumo, pressione Esc duas vezes para voltar a um turno anterior. Quando uma tarefa longa termina ou precisa de aprovação, Terminal e VS Code podem avisar. /stats estima custos depois que os preços são configurados, e trocar de modelo agora leva só um comando.
✨ Novidades
Suporte aprofundado ao DeepSeek V4
Depois do lançamento do DeepSeek V4, o Qwen Code adicionou suporte completo rapidamente. A janela de contexto é de 1M e o limite de saída é de 384K, permitindo que um Agent leia bases de código grandes e gere saídas longas em uma única execução. Também há suporte ao reasoning effort “max”, para dar mais orçamento de raciocínio ao DeepSeek em tarefas complexas. Vários problemas de compatibilidade com thinking blocks foram corrigidos, garantindo que o processo de raciocínio apareça corretamente nos fluxos mais comuns.
O que você pode fazer com isso:
- Trabalhar com arquivos enormes e repositórios inteiros usando DeepSeek V4, com menos risco de bater no limite de contexto
- Definir reasoning effort como “max” para arquitetura, raciocínio longo e tarefas complexas
- Preservar o reasoning do DeepSeek após restauração de sessão, rewind de conversa e compactação de contexto
- Usar thinking blocks corretamente em modo compatível com anthropic e em deploys de terceiros como sglang e vllm
Veja os PRs #3693 , #3800 , #3788 , #3747 , #3729
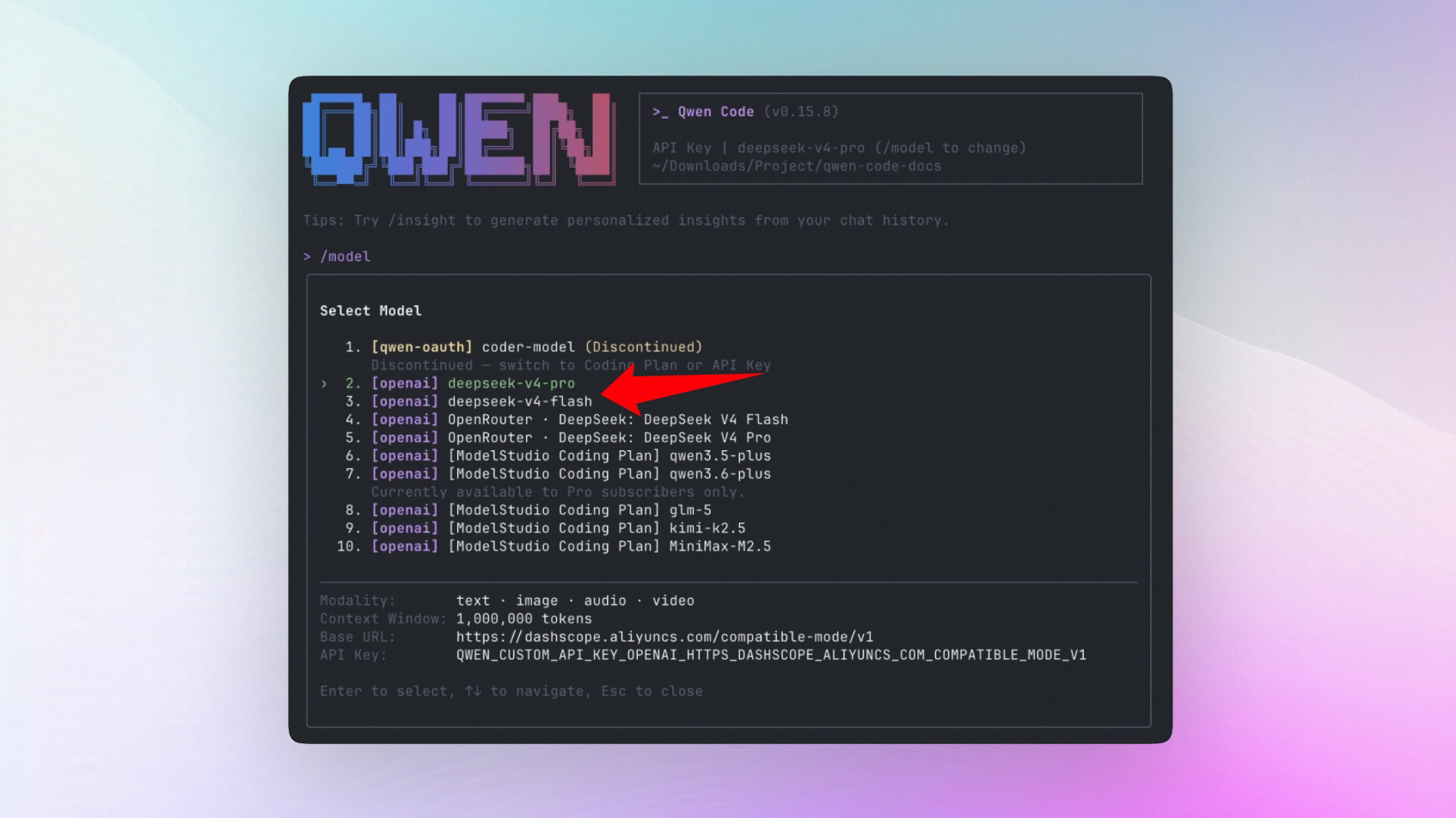
Ver, cancelar e retomar tarefas em segundo plano
Antes, comandos shell em segundo plano eram apenas colocados para rodar fora do fluxo principal. Era difícil saber se ainda estavam executando, onde estava a saída ou como parar. Agora background agents e shells em segundo plano aparecem em uma visão unificada de tarefas, com status, saída e detalhes. Se uma tarefa for interrompida, ela pausa automaticamente e pode ser retomada ou cancelada.
O que você pode fazer com isso:
- Rodar tarefas longas sem travar a conversa:
npm run dev, testes, watchers de arquivos e comandos parecidos podem seguir em segundo plano - Conferir e controlar o status a qualquer momento via
/tasksou pelo painel, incluindo caminhos de saída e cancelamento de tarefas que você não precisa mais - Recuperar com segurança após interrupções: a tarefa não se perde; você pode retomar ou abandonar
Voltar a conversa para um ponto anterior
Antes, quando uma conversa desviava do caminho, normalmente era preciso continuar corrigindo ou abrir uma nova sessão. Agora você pode pressionar Esc duas vezes ou rodar /rewind, escolher um turno anterior do usuário e voltar o histórico até aquele ponto.
O que você pode fazer com isso:
- Desfazer uma direção errada e voltar à pergunta importante com uma nova instrução
- Tentar de novo sem abrir outra sessão nem copiar o contexto anterior
- Explorar alternativas de implementação voltando ao ponto de bifurcação
Veja o PR #3441
Fluxo de revisão de código /review atualizado
O /review passou por uma atualização completa. Ele saiu de 5 agents para 9 agents, moveu as etapas de revisão que antes ficavam espalhadas no prompt para 6 subcomandos CLI multiplataforma e agora produz JSON estruturado. Basta digitar /review <link ou número do PR> para a IA buscar o código, carregar regras do projeto, rodar lint, revisar em paralelo, deduplicar, verificar CI e publicar comentários inline.
O que você pode fazer com isso:
- Revisar um PR com um comando:
/review https://github.com/xxx/pull/123 - Revisar com 9 papéis ao mesmo tempo: além de correção e segurança, entram as perspectivas de “atacante”, “plantão das 3 da manhã” e “mantenedor”
- Evitar approve com CI vermelho: CI e self-PR são detectados automaticamente e o approve pode virar comment
- Manter sugestões incertas fora do PR: achados de baixa confiança ficam apenas no terminal
- Evitar comentários duplicados: comentários Qwen existentes são reconhecidos
Veja o PR #3754

Notificações quando uma tarefa termina ou precisa de confirmação
Antes, os lembretes no terminal dependiam principalmente de um terminal bell pouco perceptível. A extensão do VS Code também não tinha sinais visuais fortes o suficiente. Agora iTerm2, Kitty e Ghostty podem mostrar notificações de desktop quando uma tarefa termina; no VS Code, há ponto na aba, bolhas de notificação e som.
O que você pode fazer com isso:
- Parar de ficar olhando o terminal durante tarefas longas
- Perceber rapidamente quando a IA precisa de aprovação de ferramenta ou resposta
- Não perder mensagens no VS Code enquanto trabalha em outras abas
/stats mostra estimativa de custo do modelo
O comando /stats agora inclui estimativa de custo. Configure modelPricing no settings.json com o preço de entrada e saída por milhão de tokens, e o /stats calcula uma estimativa a partir do consumo. Sem configuração de preço, ele continua mostrando apenas a contagem de tokens.
O que você pode fazer com isso:
- Configurar os preços dos modelos usados com frequência uma vez e deixar
/statscalcular automaticamente - Comparar o custo entre modelos depois de trocar
- Acompanhar custo em automações longas e evitar surpresas
Veja o PR #3780
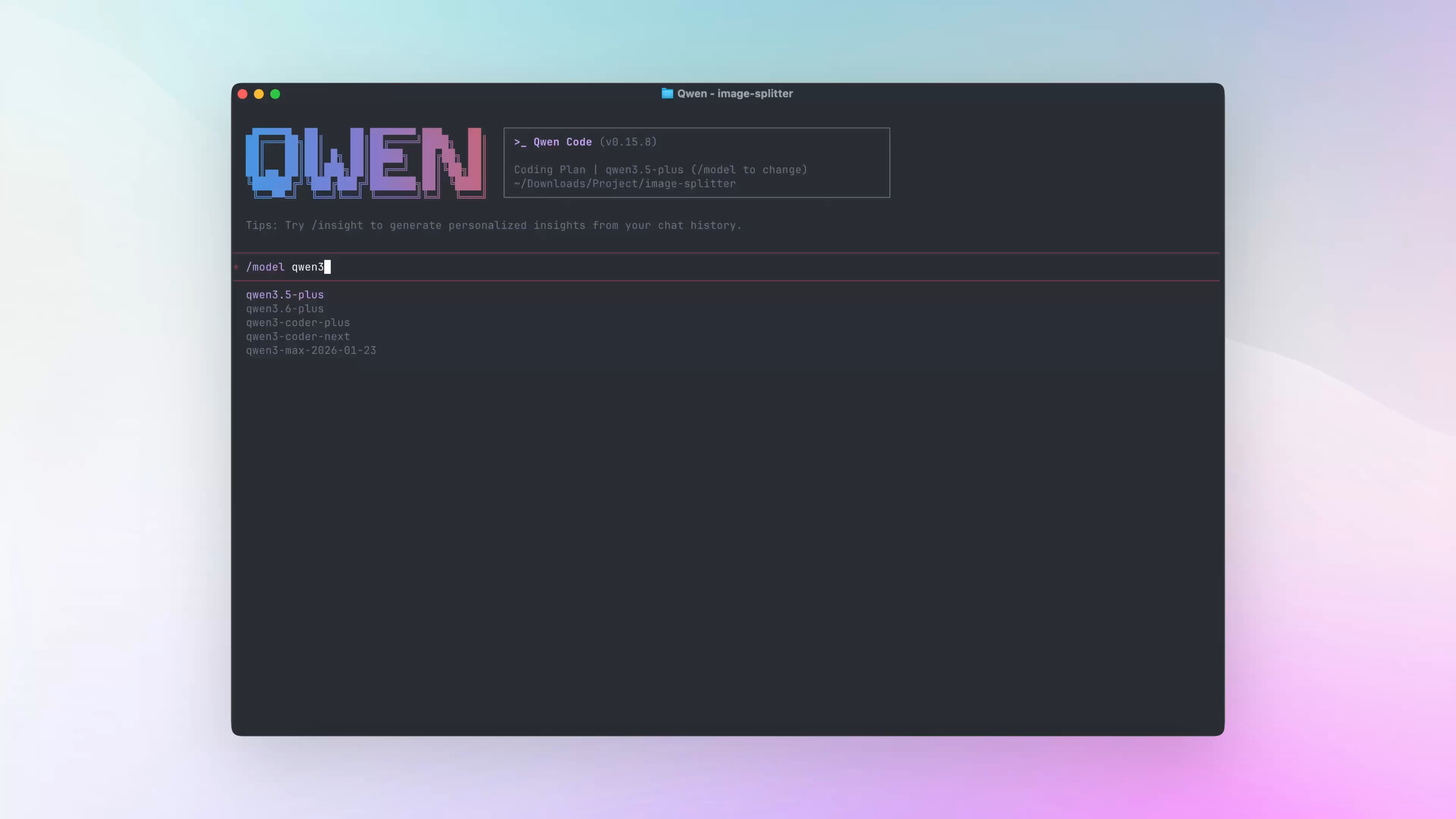
Trocar de modelo mais rápido com /model
Antes era preciso abrir o seletor /model e procurar na lista. Agora basta digitar /model nome-do-modelo.
O que você pode fazer com isso:
- Pular o seletor: por exemplo,
/model qwen3.6-plus - Comparar modelos rapidamente: pergunte com
/model A, depois mude para/model B - Usar modelos upstream diretamente depois de configurar a base URL
Veja o PR #3783
📊 Melhorias
- OpenRouter agora usa autorização pelo navegador: em vez de copiar API Key e manter a lista de modelos manualmente, use
/authpara autorizar no navegador. O Qwen Code salva a chave e busca o catálogo de modelos;/manage-modelspermite pesquisar, filtrar e ativar modelos (#3576 ) - Todo list fixa: a lista de tarefas mais recente fica acima da caixa de entrada e atualiza com as mudanças de status, sem você precisar voltar no histórico para conferir o progresso (#3507 , #3647 )
- Leitura de arquivos mais rápida e sem repetição: FileReadCache evita reler o mesmo conteúdo, deixando conversas com várias rodadas e fluxos com ferramentas mais estáveis (#3717 )
- Busca web via MCP: o provider
web_searchfoi migrado para MCP, com suporte a serviços como Bailian, Tavily e GLM WebSearch Prime (#3502 ) - Primeira chamada de modelo mais rápida: pré-conexão ao endpoint padrão na inicialização (#3318 )
- Chamadas paralelas de ferramentas mais legíveis: quando várias ferramentas rodam em paralelo, o Qwen Code mostra rótulos semânticos curtos, não apenas a contagem de ferramentas, para você entender melhor o que a IA está fazendo (#3538 )
- Caminho quente de tool calls mais rápido: menos I/O síncrono no runtime deixa tarefas longas e fluxos com várias ferramentas mais estáveis (#3581 )
- Títulos de sessão podem ser regenerados com
/rename --auto(#3540 ) - Subagents em primeiro plano entram no painel de tarefas (#3768 )
- Skills carregam mais rápido e podem ativar por caminho (#3604 )
- Status de servidores MCP na barra inferior: fica mais fácil ver se um MCP server está online e diagnosticar problemas de conexão (#3741 )
- Tempo de execução do shell mais claro (#3512 )
- Comandos longos podem ser sugeridos para execução em segundo plano (#3809 )
- VS Code suporta
/skillse/export(#2548 , #2592 ) - Configuração MCP via flag CLI: SDKs e scripts podem passar a configuração de MCP server diretamente, sem editar arquivos de configuração manualmente (#1279 )
- Descoberta MCP deduplica solicitações repetidas: requisições repetidas de descoberta de MCP server são combinadas para reduzir custo de rede na inicialização (#3818 )
- Slash commands mostram dicas de parâmetros (#3593 )
- Interface em chinês tradicional via
/language ui zh-TW(#3569 ) - Copiar no Webview do VS Code ficou mais prático (#3477 )
- Tool calls MCP mais completos no modo ACP com servidores SSE/HTTP e chamadas concorrentes (#3574 , #3463 )
🔧 Correções importantes
| PR | Versão | Correção | Impacto |
|---|---|---|---|
| #3645 | v0.15.6 | Corrigida a prioridade de seleção de modelo para argv > settings > auth env vars | Modelo passado na CLI prevalece como esperado |
| #3820 | v0.15.7 | Corrigida leitura/escrita de caminhos com caracteres especiais | Caminhos com espaços ou caracteres especiais não falham mais |
| #3525 | v0.15.1 | Corrigido estado compartilhado no parser streaming de tool calls | Saídas multi-turno não se misturam |
| #3533 | v0.15.1 | Corrigido loop de renderização da slash completion | A UI não trava ao digitar slash commands |
| #3753 | v0.15.7 | Proxy não aplicado corrigido | Ambientes corporativos e intranet funcionam melhor |
| #3656 | v0.15.4 | Recuperação de registros JSONL colados da sessão | Registros de sessão anormais ficam mais fáceis de recuperar sem perder o contexto |
| #3547 | v0.15.3 | Rerenders desnecessários no histórico | Histórico mais fluido |
| #3600 | v0.15.4 | Parsing de comandos shell multilinha | Menos divisão incorreta de comandos |
| #3531 | v0.15.2 | Ordem de prompts históricos reenviados | Prompts reenviados voltam para a posição mais recente, mantendo o contexto posterior coerente |
| #3544 | v0.15.2 | Resíduos do protocolo de teclado Kitty após SIGINT | Terminal não mostra caracteres estranhos após interrupção |
| #3617 | v0.15.4 | Formato de resultado multimídia em modo OpenAI estrito | Providers compatíveis com OpenAI ficam mais estáveis |
| #3691 | v0.15.4 | Descrição ausente em fragmentos reasoning com subject | Reasoning aparece de forma mais completa |
| #3559 | v0.15.2 | pages vazio em ReadFile | Leitura de arquivos não falha por parâmetro vazio |
| #3677 | v0.15.7 | Parsing de thinking tags do MiniMax | Pensamento do MiniMax aparece corretamente |
| #3615 | v0.15.6 | Docs LSP, limites de caminho e taxa de tool calls | Ferramentas de inteligência de código ficam mais confiáveis |
| #3618 | v0.15.6 | Enter em slash command no VS Code só preenche a entrada | Dá para completar parâmetros antes de enviar |
| #3752 | v0.15.6 | Persistência de diretórios adicionados | Diretórios de trabalho são salvos para a próxima vez |
🎈 Outras mudanças
- Tarefas Auto-memory dream podem ser canceladas manualmente, então a organização de memória em segundo plano não fica mais presa depois de iniciada (#3836 )
- Auto-memory rollback não bloqueia mais a requisição principal, deixando a conversa mais fluida enquanto a memória é organizada em segundo plano (#3814 )
- Erros de API duplicados no modo não interativo foram corrigidos, deixando a saída de erro mais limpa (#3749 )
- VS Code corrigiu slash command completion após envio de mensagem (#3609 )
qwen authganhou opção de API Key (#3624 )- Corrigido erro de dispatch da fila de slash commands (#3523 )
- Corrigido desalinhamento de chaves i18n entre chinês e inglês (#3534 )
- Tratamento de erros OAuth2 melhorado (#3481 )
/reviewlocal respeita/language(#3611 )- Conversor OpenAI ficou stateless (#3550 )
- Exportação de Telemetry usa serialização JSON segura (#3630 )
- Java SDK aceita variáveis de ambiente customizadas ao iniciar a CLI (#3543 )
- TypeScript SDK v0.1.7 publicado com CLI v0.15.3 (#3688 )
.gitignoreinclui.codex(#3665 )- Removido rastreamento de uso de Token de ferramentas para reduzir ruído nas métricas internas (#3727 )
- Documentação de desenvolvimento adicionou skills, agents e fluxo AGENTS.md (#3575 )
- Release workflow adicionou PR de merge-back estável (#3764 )
- Auto-merge de release do SDK agora usa squash merge (#3690 )
- Instruções do template de PR foram atualizadas (#3522 )
- Documentação de Telemetry adicionou entrada do console Alibaba Cloud (#3498 )
👋 Boas-vindas aos novos contribuidores
- @alex-musick — troca rápida de modelo com
/model(#3783 ) - @qiuqiuwen25 — leitura/escrita de caminhos com caracteres especiais (#3820 )
- @umut-polat — correção de erro API duplicado no modo não interativo (#3749 )
- @cyphercodes — persistência de diretórios adicionados (#3752 )
- @eliird — configuração MCP via CLI (#1279 )
- @jordimas — suporte ao catalão (#3643 )
- @mohitsoni48 — formato de resultado de ferramenta no modo OpenAI estrito (#3617 )
- @Jerry2003826 — parsing de comandos shell multilinha (#3600 )
- @MikeWang0316tw — interface em chinês tradicional (#3569 )
- @lawrence3699 — variáveis de ambiente customizadas no Java SDK (#3543 )
- @fyc09 — preservação do reasoning do DeepSeek na restauração de sessão (#3590 , #3737 )
Atualização: execute npm i @qwen-code/qwen-code@latest -g para instalar a versão mais recente.
Se tiver dúvidas ou sugestões, use GitHub Issues .