Qwen Code Semanal: Channels Multiplataforma, Tarefas Cron Agendadas, Modo /plan, Lançamento do Qwen 3.6 Plus
Esta semana lançamos duas versões de funcionalidades v0.14.0 e v0.14.2, além de duas versões de correção v0.13.2 e v0.14.1.
v0.14.0 é uma atualização importante:
- O sistema Channels liberta o Qwen Code do terminal, permitindo operação remota através do Telegram, WeChat, DingTalk e outras plataformas;
- Tarefas Cron agendadas permitem que a IA execute automaticamente trabalhos repetitivos conforme um cronograma;
- O modelo Qwen 3.6 Plus foi oficialmente lançado. v0.14.1 traz sugestões de acompanhamento, alternância de modo de verbosidade e outras melhorias de experiência.
- v0.14.2 adiciona o comando
/planem modo de planejamento, retenção de blocos de pensamento entre turnos, upgrade de tokens de saída adaptativos (padrão 8K + upgrade automático para 64K), além de workflow de correção de bugs integrado e habilidades de depuração.
Agradecemos aos novos contribuidores desta semana @chinesepowered, @pic4xiu, @YingchaoX, @euxaristia, @kulikrch, @nsalvacao, @mj4444ru, @chiga0 🎉
✨ Novos Recursos
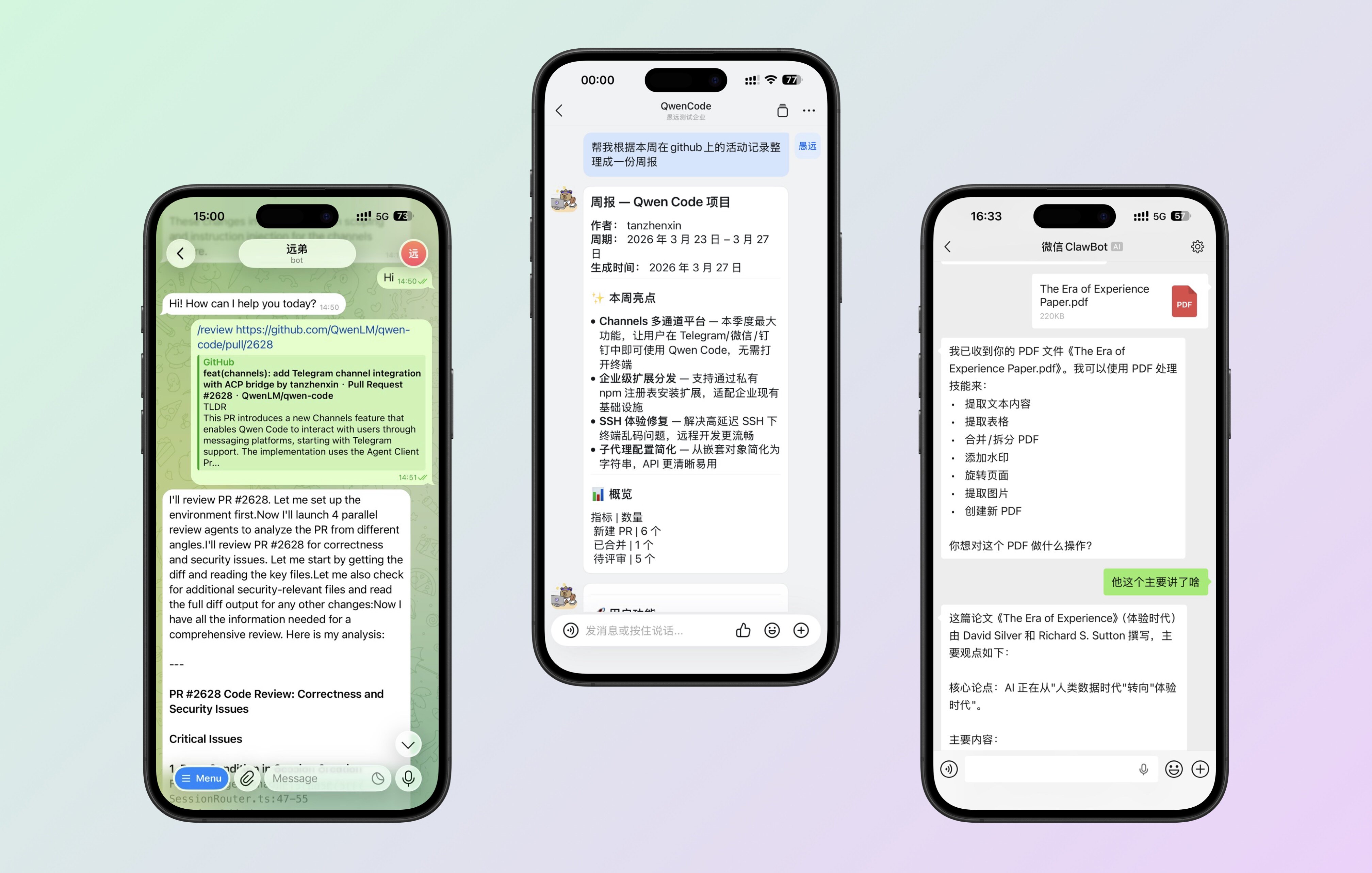
Channels: Opere o Qwen Code Remotamente via DingTalk, Telegram, WeChat
O Qwen Code não está mais limitado ao terminal. O sistema Channels suporta acesso baseado em plugins a múltiplas plataformas — atualmente suportando Telegram, WeChat e DingTalk. Você pode enviar uma mensagem ao Bot pelo celular e fazê-lo executar tarefas no seu servidor.
O que você pode fazer:
- Fora de casa, envie uma mensagem ao Qwen Code via Telegram para executar um script ou verificar logs
- Mencione @o bot em um grupo DingTalk para lidar com tarefas relacionadas a código para a equipe
- Envie uma mensagem rápida no WeChat para operar remotamente seu ambiente de desenvolvimento
Veja PR #2628
Tarefas Cron Agendadas: Deixe a IA Trabalhar Conforme um Cronograma
Uma nova ferramenta Cron permite configurar tarefas recorrentes agendadas dentro da sessão atual. A IA as executará automaticamente conforme seu cronograma definido sem que você precise monitorar.
O que você pode fazer:
- Verificar automaticamente se os testes passam a cada 30 minutos
- Puxar automaticamente o código mais recente e executar um build toda manhã
- Monitorar arquivos de log conforme um cronograma e notificá-lo quando anomalias forem detectadas
Veja PR #2731
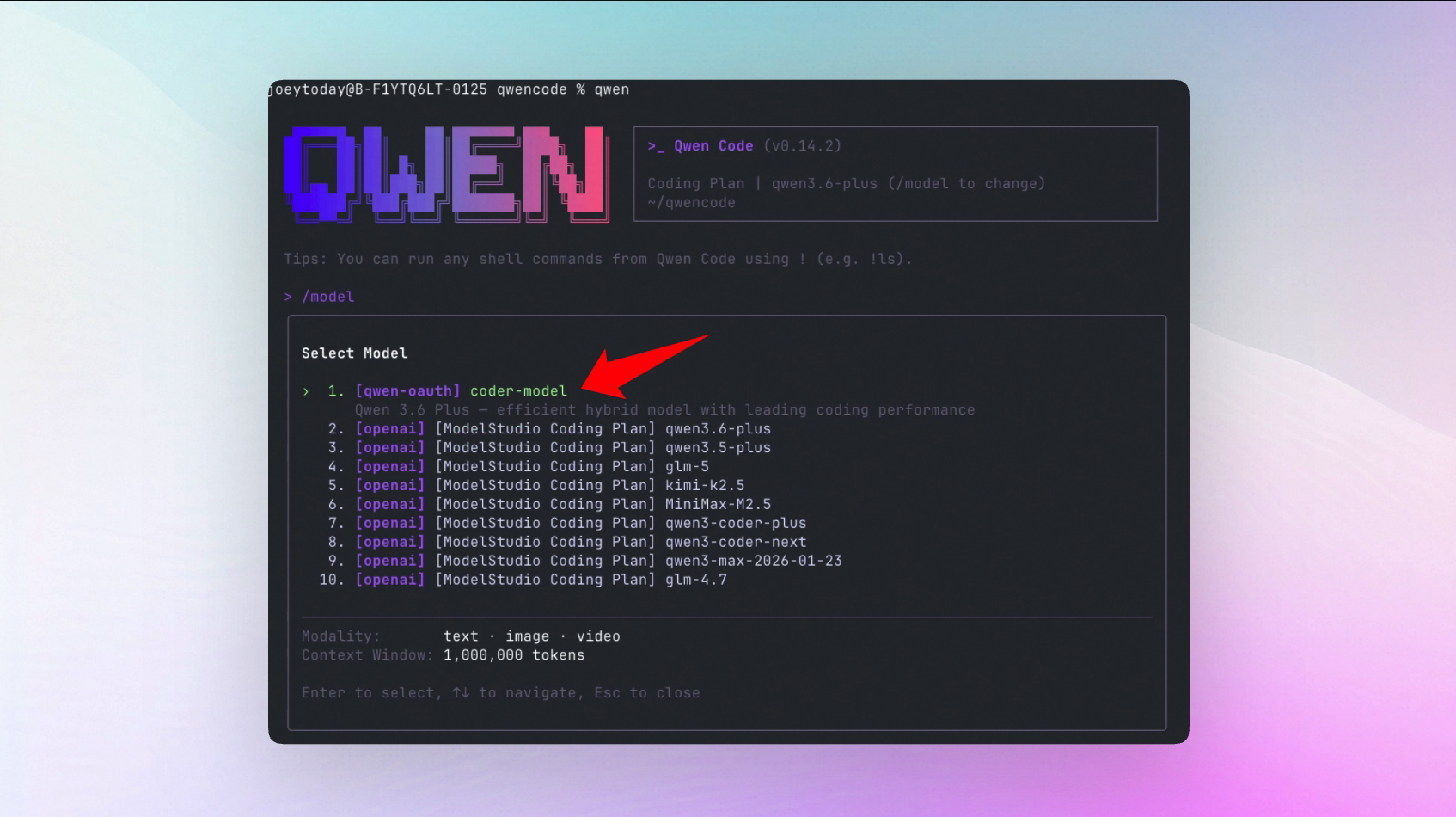
Como ativar?
Adicione o seguinte ao ~/.qwen/settings.json:
{
"experimental":{
"cron": true
}
}Lançamento do Modelo Qwen 3.6 Plus
O Qwen 3.6 Plus está oficialmente disponível no Qwen Code, gratuito para uso. Seu desempenho em programação é comparável ao GPT-5 e Claude 3.7 Sonnet, com vantagens notáveis em compreensão de chinês e processamento de contexto longo. O Plano Coding do Alibaba Cloud ModelStudio também está disponível.
O que você pode fazer:
- Usar o modelo Qwen 3.6 Plus mais recente diretamente no Qwen Code
- 1.000 chamadas gratuitas/dia, contexto de 1 milhão de tokens
- Melhor experiência para cenários de programação em chinês
Veja PR #2820
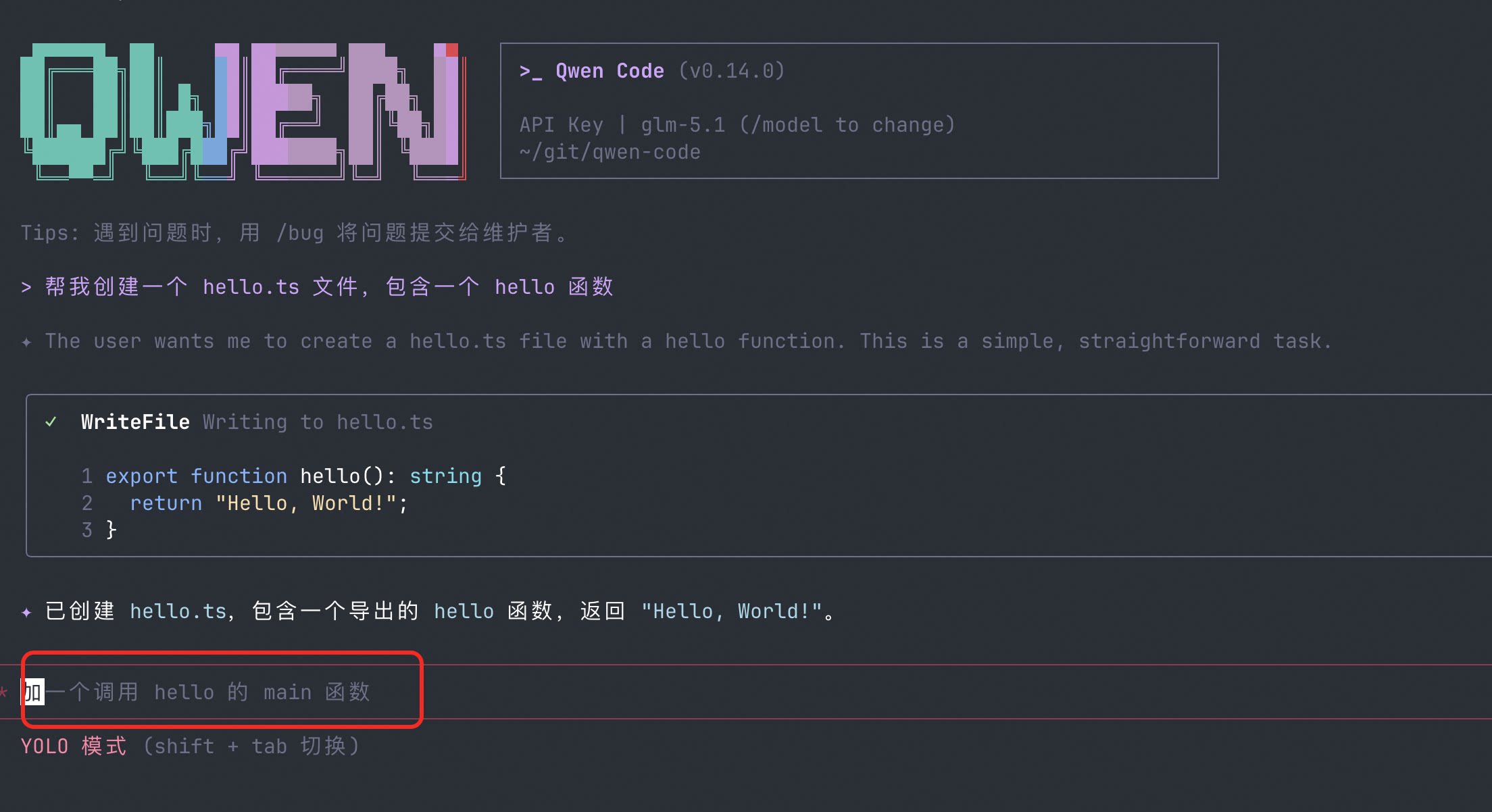
Sugestões de Acompanhamento: A IA Diz o Que Fazer em Seguida
Após concluir uma tarefa, a IA fornece automaticamente 2-3 sugestões de acompanhamento. Não precisa pensar “o que fazer agora” — basta clicar para continuar.
O que você pode fazer:
- Depois de escrever um componente, a IA sugere “Quer adicionar testes unitários?” — basta clicar para começar
- Depois de corrigir um bug, a IA sugere “Quer verificar lugares semelhantes?” — economiza seu tempo de reflexão
- Quando iniciantes não sabem o que fazer em seguida, as sugestões de acompanhamento servem como navegação
Veja PR #2525
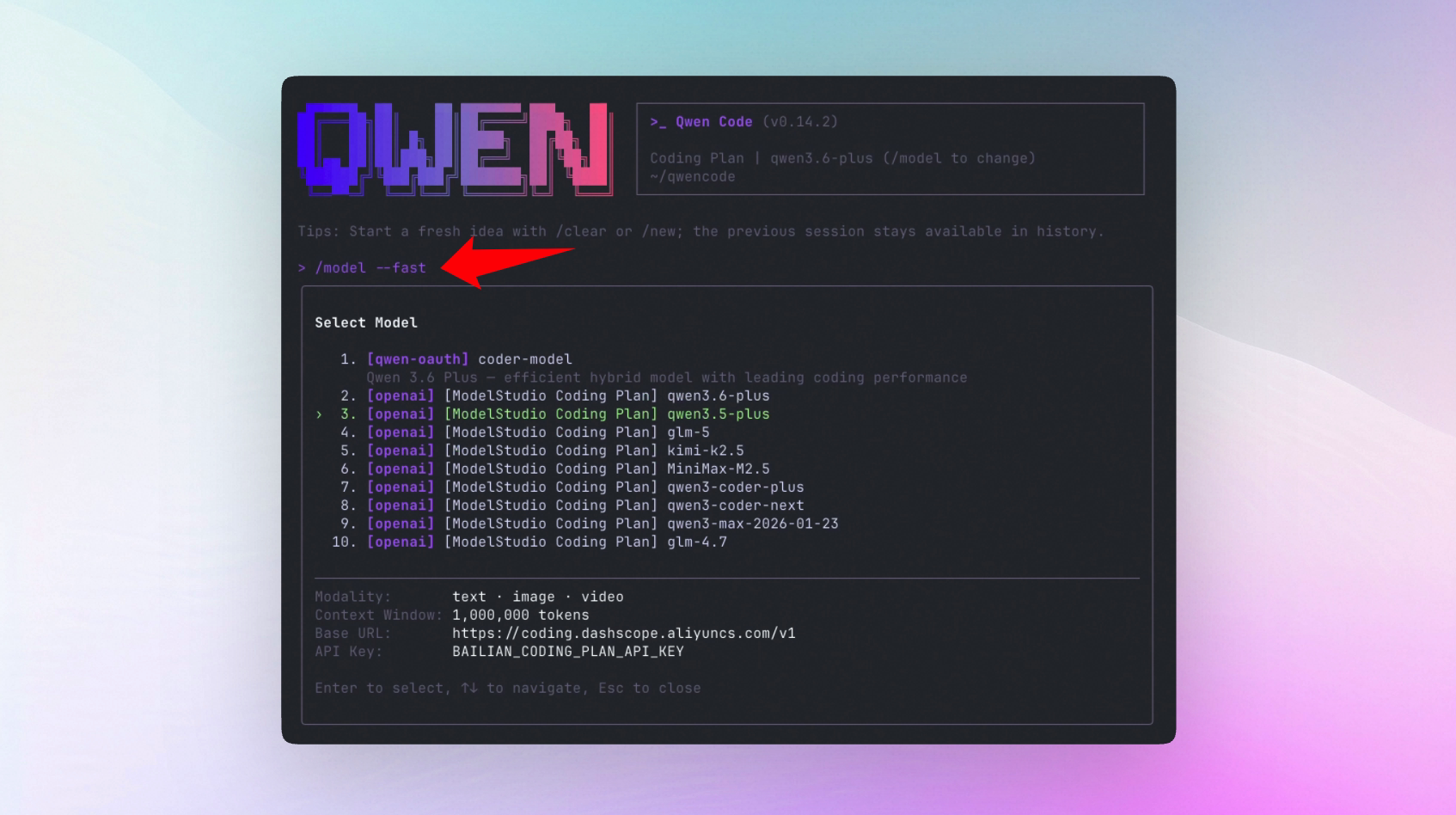
Como ativar?
Adicione o seguinte ao ~/.qwen/settings.json:
{
"ui":{
"enableFollowupSuggestions": true
}
}Para tempos de resposta mais rápidos nas sugestões, você pode usar /model --fast para especificar um modelo leve dedicado às sugestões em segundo plano.
Seleção de Modelo Cruzado para Sub-Agentes: Modelos Diferentes para Tarefas Diferentes
Sub-agentes agora podem usar modelos diferentes do agente principal. Use um modelo poderoso para a tarefa principal para garantir qualidade, e um modelo leve para sub-tarefas para acelerar — combinações flexíveis que economizam tokens sem sacrificar qualidade.
O que você pode fazer:
- Usar Qwen 3.6 Plus para a tarefa principal e um modelo leve para sub-tarefas, reduzindo o consumo de tokens enquanto mantém a qualidade para tarefas críticas
- Diferentes tipos de sub-tarefas recebem automaticamente o modelo mais adequado
Veja PR #2698
Como começar?
Crie um arquivo Skill de sub-agente especificando um modelo diferente:
---
name: test-cross-provider
description: Teste de Agent cross-provider
model: openai:gpt-4o
---
Você é um assistente de teste. Por favor, apresente-se brevemente, incluindo o nome do modelo que está usando.Em seguida, diga ao Qwen Code para invocar este sub-agente na conversa.
Alternância de Verbosidade Ctrl+O: Mude o Nível de Detalhe com Uma Tecla
Pressione Ctrl+O para alternar entre os modos verbose (detalhado) e compact (conciso). Veja a saída detalhada ao depurar, mude para o modo compacto para uso diário — sem necessidade de alterar configurações.
O que você pode fazer:
- Mudar para o modo verbose ao depurar para ver o processo de execução completo
- Mudar para o modo compact para uso diário para uma interface mais limpa
- Alternar a qualquer momento sem reiniciar ou editar arquivos de configuração
Veja PR #2770
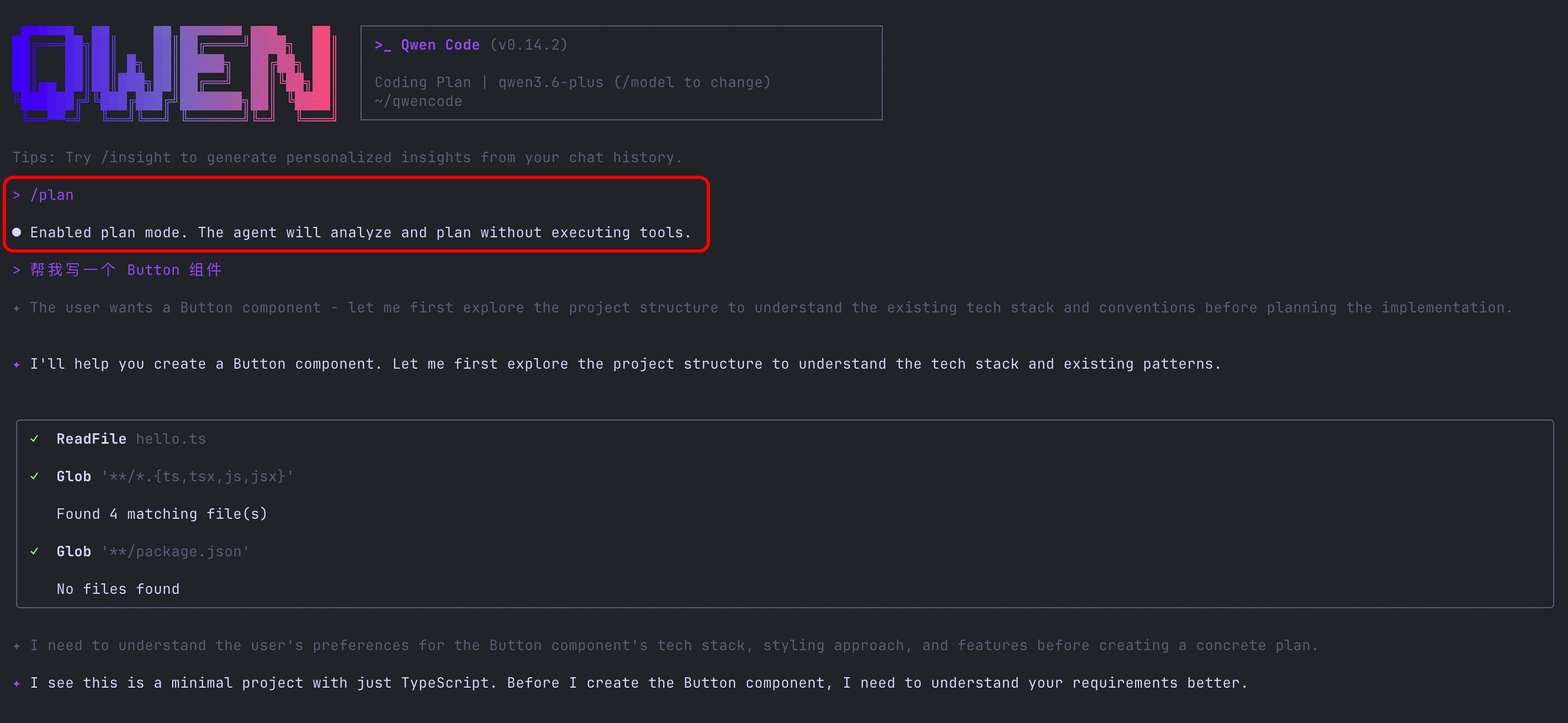
Comando /plan: Planeje Antes de Agir
O novo comando /plan permite entrar no modo de planejamento com um comando. A IA primeiro fornecerá um plano de execução completo, e você confirma antes de começar a execução. Perfeito para tarefas complexas — veja o panorama completo primeiro, depois avance passo a passo.
O que você pode fazer:
- Antes de refatorar um módulo grande, peça à IA para listar todos os arquivos e etapas que precisam ser alterados
- Revise o plano para tarefas de múltiplas etapas primeiro para evitar que a IA desvie e tenha que recomeçar
- Na colaboração em equipe, gere um plano para os colegas confirmarem antes de executar
Veja PR #2921
Tokens de Saída Adaptativos: Respostas Não São Mais Truncadas
Os tokens de saída padrão são 8K. Quando a IA detecta que uma resposta está sendo truncada, ela automaticamente faz upgrade para 64K e tenta novamente. Não precisa ajustar parâmetros manualmente — a IA determina quanto espaço de resposta precisa por conta própria.
O que você pode fazer:
- Geração de arquivos longos não é mais truncada — conteúdo completo em uma única saída
- Geração de código complexo sem precisar juntar segmentos
- Não precisa configurar max_tokens manualmente — a IA se adapta automaticamente
Veja PR #2898
Retenção de Blocos de Pensamento Entre Turnos
O processo de pensamento da IA (thinking block) agora pode ser retido entre turnos de conversa, com limpeza automática durante o tempo ocioso. Em conversas de múltiplos turnos, a IA pode continuar melhor sua cadeia de raciocínio anterior para respostas mais coerentes.
Veja PR #2897
📊 Melhorias
| PR | Versão | Melhoria | Impacto |
|---|---|---|---|
| #2781 | v0.14.0 | Hooks GA: removida flag experimental, adicionada UI de estado desabilitado | Pode desabilitar temporariamente um Hook sem deletar a config, mais estável como recurso oficial |
| #2687 | v0.14.0 | /review aprimorado: adicionadas etapas de validação e controle de falsos positivos, suporte a comentários em PRs | Resultados de review mais precisos, menos avisos sem sentido |
| #2776 | v0.14.1 | /btw pergunta lateral aprimorada: qualidade de prompt melhorada, adicionado Ctrl+C/D para cancelar | Experiência de pergunta lateral mais fluida, pressione Ctrl+C a qualquer momento para cancelar |
| #2719 | v0.14.0 | Extensões suportam instalação via npm | Além de URLs do GitHub, agora você pode instalar extensões do registro npm |
| #2428 | v0.14.0 | Reconexão automática MCP, adicionado comando /mcp reconnect | MCP se recupera automaticamente após desconexão, sem necessidade de reiniciar toda vez |
| #2889 | v0.14.1 | Orientação para operações perigosas: prompt do sistema adiciona orientação de comportamento para operações perigosas | A IA confirmará mais cuidadosamente antes de executar exclusões, sobrescritas e outras operações, reduzindo operações acidentais |
| #2659 | v0.14.0 | Otimização do /compress: tratamento correto de conversas intensivas em chamadas de ferramentas | Comprimir conversas longas não perde mais o contexto chave |
| #2595 | v0.14.1 | Padronização de rótulos de ferramentas WebUI | Nomes de ferramentas exibidos de forma mais consistente e clara na interface WebUI |
| #2954 | v0.14.2 | Sugestões de acompanhamento desabilitadas por padrão | Não será interrompido por sugestões automáticas, ative nas configurações quando necessário |
🔧 Correções Importantes
| PR | Versão | Correção | Impacto |
|---|---|---|---|
| #2733 | v0.13.2 | Corrigida resolução de caminho node-pty no Windows Git Bash | Usuários do Windows Git Bash não encontram mais erros de inicialização |
| #2656 | v0.13.2 | Corrigido lag do /clear e tecla ESC causado pelo sistema Hooks | Operações de limpar tela e cancelar estão fluidas novamente |
| #2707 | v0.13.2 | Preservar fins de linha originais (CRLF/LF) ao editar arquivos | Sem mais adulteração de fins de linha durante colaboração multiplataforma |
| #2718 | v0.13.2 | Corrigido vazamento de resposta do terminal em ambientes SSH de alta latência | A saída não serializa mais durante desenvolvimento remoto SSH |
| #2777 | v0.14.0 | Atualizado node-pty para corrigir vazamento de descritores de arquivo PTY no macOS | Sem mais lag por vazamentos de FD durante uso prolongado |
| #2662 | v0.14.0 | Limpar processos órfãos ao fechar abas, limpar subprocessos MCP ao sair | Sem mais processos em segundo plano persistentes consumindo recursos após sair |
| #2884 | v0.14.1 | Restaurado atalho ? no modo normal do vim | O atalho de busca dos usuários vim funciona normalmente novamente |
| #2837 | v0.14.1 | Removida detecção de arrastar aspas, corrigido atraso de entrada | Sem mais atraso de entrada perceptível ao digitar |
| #2834 | v0.14.1 | /theme restaura o tema anterior ao cancelar | Cancelar a troca de tema não fica mais preso em um estado intermediário |
| #2822 | v0.14.1 | Prevenir falha do ideCommand de afetar todos os comandos slash | Um erro de comando único não torna mais todos os comandos indisponíveis |
| #2804 | v0.14.1 | Conexão ACP adiciona retry e reconexão automática | Integração VS Code mais estável, recuperação automática após desconexão |
| #2802 | v0.14.1 | Nova aba do VS Code herda seleção de modelo | Novas abas não requerem mais re-seleção do modelo |
| #2959 | v0.14.2 | Corrigida tela branca do webview VS Code 0.14.1 | O painel do VS Code não mostra mais tela branca após atualizar para v0.14.1 |
| #2995 | v0.14.2 | Corrigido erro csiUPrefix no Linux/Wayland | Usuários Linux Wayland não encontram mais erros de entrada |
| #2976 | v0.14.2 | Hooks preservam código de saída null na terminação por sinal | Hooks não reportam mais incorretamente código de saída como 0 quando terminados por sinal |
| #2858 | v0.14.1 | Correção de compatibilidade de parâmetros de ferramentas MCP (schema anyOf/oneOf) | Mais parâmetros de ferramentas MCP podem ser corretamente analisados, reduzindo erros de chamada |
| #2943 | v0.14.1 | Header iLink-App-Id ausente no Channel WeChat | Conexão do Channel WeChat mais estável, não falha mais por header ausente |
🎈 Outras Melhorias
| PR | Melhoria | Impacto |
|---|---|---|
| #2623 | Skill qc-helper integrado e docs de referência qwen-code-claw | Novos usuários obtêm automaticamente orientação de habilidades integradas na inicialização, onboarding mais rápido |
| #2715 | Otimização da documentação envKey: instruções de uso e exemplos de campos env mais claros | Sem mais adivinhação de formatos de parâmetros ao configurar variáveis de ambiente |
| #2714 | Unificação Bailian → ModelStudio | Nomes de marca unificados na documentação, novos usuários não serão confundidos por nomes antigos |
| #2696 | Otimização da UI de eventos Hooks: mudança para entradas de histórico dedicadas | O histórico de conversas mostra claramente quais operações foram acionadas por Hooks |
| #2463 | Correção de renderização de tabelas Markdown | Tabelas geradas pela IA não têm mais problemas de formatação |
| #2455 | Persistência de configuração de modelo | Configurações de modelo personalizadas não são mais perdidas após reiniciar |
| #2763 | Modo Plan suporta aprovação de web fetch | A IA agora pode navegar em páginas web durante a fase de planejamento |
| #2586 | Correção de saída do modo YOLO | Não fica mais preso no modo de planejamento |
| sdk-typescript-v0.1.6 | SDK TypeScript v0.1.6 | API mais completa para desenvolvedores integrando capacidades do Qwen Code |
👋 Bem-vindos Novos Contribuidores
- @chinesepowered — Corrigiu limpeza do listener de abort dos Hooks, atualização de cache de sub-agentes, fallback de mensagens do Telegram e mais
- @pic4xiu — Corrigiu timing de commit de mensagens do sistema Hook, removeu configurações de proxy duplicadas do WebFetchTool
- @YingchaoX — Restaurou atalho ? no modo normal do vim
- @euxaristia — Removeu detecção de arrastar aspas para corrigir atraso de entrada
- @kulikrch — /theme restaura o tema anterior ao cancelar
- @nsalvacao — Corrigiu exit_plan_mode no modo YOLO
- @mj4444ru — Corrigiu escape de separadores de células de tabela Markdown
- @chiga0 — Implementou alternância de modo de verbosidade Ctrl+O
Como atualizar: Execute npm install -g @qwen-code/qwen-code@latest para atualizar para a versão mais recente.
Se você tiver perguntas ou sugestões, sinta-se à vontade para dar feedback em GitHub Issues !